Java 8 新特性 - 菜鸟
Java 8 Tutorials
Java 8 Tutorials
包含一些原计划在 Java 7 中却延迟发布的功能。
简介 我们通常所说的接口的作用是用于定义一套标准、约束、规范等,接口中的方法只声明方法的签名,不提供相应的方法体,方法体由对应的实现类去实现。
在JDK1.8中打破了这样的认识,接口中的方法可以有方法体,但需要关键字static或者default来修饰,使用static来修饰的称之为静态方法,静态方法通过接口名来调用,使用default来修饰的称之为默认方法,默认方法通过实例对象来调用。
静态方法和默认方法的作用: 静态方法和默认方法都有自己的方法体,用于提供一套默认的实现,这样子类对于该方法就不需要强制来实现,可以选择使用默认的实现,也可以重写自己的实现。当为接口扩展方法时,只需要提供该方法的默认实现即可,至于对应的实现类可以重写也可以使用默认的实现,这样所有的实现类不会报语法错误:Xxx不是抽象的, 并且未覆盖Yxx中的抽象方法。
默认方法(default) Java 8 默认方法 - 菜鸟
默认方法就是接口可以有实现方法,而且不需要实现类去实现 。
用法:
使用 default 关键字修饰,访问权限默认且一定为 public。
只能在接口中定义,且必须加 body 实现
支持重载
子类可重写:子接口 重写成 default 方法 ;子接口 重写成 抽象方法 ;子类 重写成 普通方法 ;
JDK1.8 可以通过反射判断接口的某个方法是否为 default 方法
1 2 Method m = Chinese.class.getMethod("speak" );System.out.println("It is " +m.isDefault()+" that " +m.getName()+" is default method" );
为什么要有这个特性?
首先,之前的接口是个双刃剑,好处是面向抽象而不是面向具体编程,缺陷是,当需要修改接口时候,需要修改全部实现该接口的类,目前的 java 8 之前的集合框架没有 foreach 方法,通常能想到的解决办法是在JDK里给相关的接口添加新的方法及实现。然而,对于已经发布的版本,是没法在给接口添加新方法的同时不影响已有的实现。所以引进的默认方法。他们的目的是为了解决接口的修改与现有的实现不兼容的问题。
多个接口默认方法相同
一个类实现了多个接口,且这些接口有相同的默认方法,那么这个类就不知道继承哪个接口的默认方法,编译器会报错。解决方案如下:
1 2 3 4 5 6 7 8 9 10 11 public interface Vehicle { default void print () { System.out.println("我是一辆车!" ); } } public interface FourWheeler { default void print () { System.out.println("我是一辆四轮车!" ); } }
方案一
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public interface Car extends Vehicle , FourWheeler { @Override default void print () { System.out.println("我是一辆四轮汽车!" ); } } public class Car implements Vehicle , FourWheeler { @Override public void print () { System.out.println("我是一辆四轮汽车!" ); } }
方案二 super 来调用指定接口的默认方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 public interface Car extends Vehicle , FourWheeler { @Override default void print () { Vehicle.super .print(); } } public class Car implements Vehicle , FourWheeler { @Override public void print () { Vehicle.super .print(); } }
静态方法(static) 接口可以定义静态方法。
用法:
使用 static 关键字修饰,访问权限默认且一定为 public。
可以在类、接口、枚举中定义 (注解类型除外),必须加 body 实现
支持重载
子类不可重写。
提示:静态方法属于类,无论在哪里定义,都必须有 body 实现。
1 2 3 4 5 6 7 8 9 10 public interface Vehicle { default void print () { System.out.println("我是一辆车!" ); } static void blowHorn () { System.out.println("按喇叭!!!" ); } }
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public class Java8Tester { public static void main (String args[]) { Vehicle vehicle = new Car (); vehicle.print(); } } interface Vehicle { default void print () { System.out.println("我是一辆车!" ); } static void blowHorn () { System.out.println("按喇叭!!!" ); } } interface FourWheeler { default void print () { System.out.println("我是一辆四轮车!" ); } } class Car implements Vehicle , FourWheeler { public void print () { Vehicle.super .print(); FourWheeler.super .print(); Vehicle.blowHorn(); System.out.println("我是一辆汽车!" ); } }
函数式接口(@FunctionalInterface) Java 8 函数式接口 - 菜鸟
函数式接口 (Functional Interface) 就是一个有且仅有一个抽象方法 ,但是可以有多个非抽象方法 的接口。
函数式接口可以被隐式转换为 Lambda 表达式。
函数式接口用途 主要用在 Lambda 表达式和方法引用(实际上也可认为是 Lambda 表达式)上。Lambda 表达式为函数式接口提供实现。
如下定义了一个函数式接口:
1 2 3 4 5 @FunctionalInterface interface GreetingService { void sayMessage (String message) ; }
那么就可以使用 Lambda 表达式来表示该接口的一个实现 (注:JAVA 8 之前一般是用匿名对象实现 ):
1 GreetingService greetService1 = message -> System.out.println("Hello " + message);
关于 @FunctionalInterface 注解 Java 8 为函数式接口引入了一个新注解 @FunctionalInterface,主要用于编译级错误检查 ,加上该注解,当你写的接口不符合函数式接口定义的时候,编译器会报错。
加不加 @FunctionalInterface 对于接口是不是函数式接口没有影响,该注解只是提醒编译器去检查该接口是否仅包含一个抽象方法。
允许定义默认方法 函数式接口里是可以包含默认方法,因为默认方法不是抽象方法,其有一个默认实现,所以是符合函数式接口的定义的;
允许定义静态方法 函数式接口里是可以包含静态方法,因为静态方法不能是抽象方法,是一个已经实现了的方法,所以是符合函数式接口的定义的;
允许重写java.lang.Object里的public方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class Test { public static void main (String[] args) { InterfaceA i = null ; i.toString(); i.equals("" ); i.hashCode(); } } @FunctionalInterface interface InterfaceA { @Override String toString () ; void finalize () ; }
接口是否继承于Object类?
推荐连接: 接口是否继承于Object类
Interface 并没有继承 Object 类,接口中的方法有三个来源(这不是 jdk 8 的特性 ) :
接口声明的方法
父接口声明的方法
当接口没有直接的 SuperInterface 时,Java 接口的特殊处理会隐式地声明 Object 类里所有 public 方法。也可以手动在接口中显式声明 (即 override )。不算抽象方法 。finalize())不会被隐式的声明。也就意味着,如果在接口中定义 finalize() 方法,那它就算抽象方法 。
JDK中的函数式接口 函数式接口可以对现有的函数友好地支持 Lambda 。
JDK 1.8 之前已有的函数式接口:
java.lang.Runnable
java.util.concurrent.Callable
java.security.PrivilegedAction
java.util.Comparator
java.io.FileFilter
java.nio.file.PathMatcher
java.lang.reflect.InvocationHandler
java.beans.PropertyChangeListener
java.awt.event.ActionListener
javax.swing.event.ChangeListener
JDK 1.8 新增的函数式接口:
函数式接口示例: Java 8 函数式接口 - 菜鸟
Lambda表达式 Java 8 Lambda 表达式 - 菜鸟
推荐链接: 学习Javascript闭包 (Closure) - 阮一峰 、 匿名函数与闭包的区别
简介: Lambda 表达式是一个 匿名函数 ,官方称为 lambda 表达式,非官方亦称 闭包 ,它是推动 Java 8 发布的最重要新特性。
Lambda 表达式允许把函数作为一个方法的参数(函数作为参数传递进方法中)。
使用 Lambda 表达式可以使代码变的更加简洁紧凑。
语法: 1 2 3 (parameters) -> expression 或 (parameters) ->{ statements; }
特征:
**可选类型声明:**不需要声明参数类型,编译器可以统一识别参数值。
**可选的参数圆括号:**一个参数无需定义圆括号,但多个参数需要定义圆括号。
**可选的大括号:**如果主体包含了一个语句,就不需要使用大括号。
**可选的返回关键字:**如果主体只有一个表达式返回值则编译器会自动返回值,大括号需要指定明表达式返回了一个数值。
作用: Lambda 表达式主要用来定义行内执行的方法类型接口。
Lambda 表达式免去了使用匿名方法的麻烦,并且给予Java简单但强大的 函数式编程 能力。
Lambda表达式与匿名对象相比: 相同:
可以直接访问外层环境的变量,但此变量不允许被后面的代码修改,无论是在内部还是外层,否则会编译错误(即:外层环境的变量,隐性的具有 final 语义)。
不同:
1、作用域
Lambda 表达式:基于词法作用域 ,也就是说 Lambda 表达式函数体里面的变量和它外层环境的变量具有相同的语义(也包括 Lambda 表达式的形式参数)。简言之,Lambda 表达式中不允许 声明与外层环境的变量同名的形式参数或者局部变量。代码块亦是如此。
匿名对象:拥有新的作用域,允许 声明与外层环境的变量同名的形式参数或者局部变量。
2、this关键字
Lambda 表达式:内部和外部也拥有相同的语义,所以其内部 this 代表外部对象的引用。代码块亦是如此。
匿名对象:其中的 this 代表该匿名对象的引用。
3、继承
Lambda 表达式:不会从超类(supertype)中继承任何变量。超类不允许有其他抽象方法 (函数式接口 )。
匿名对象:会继承超类中任何变量和抽象方法,且必须实现全部抽象方法。
方法引用 Java 8 方法引用 - 菜鸟
Java8 中引入方法引用新特性,用于简化应用对象方法的调用,方法引用是用来直接访问类和实例已经存在的方法或构造方法。
方法引用提供了一种引用而不执行方法的方式,它需要由兼容的函数式接口构成目标类型上下文。计算时,方法引用会创建函数式接口的一个实例。
当Lambda表达式只执行一个方法调用时,可替换成其等效的方法引用。
方法引用是 一种更简洁易懂的 Lambda 表达式 。
方法引用使用一对冒号 :: 。
IPhone类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 import java.util.Date;import java.util.function.BiFunction;import java.util.function.Supplier;public class IPhone { private Long id; private String name; private Long price; private Date createDate; public IPhone () { } public IPhone (Long id) { this .id = id; } public IPhone (Long id, String name) { this .id = id; this .name = name; } public IPhone (Long id, String name, Long price) { this .id = id; this .name = name; this .price = price; } public IPhone (Long id, String name, Long price, Date createDate) { this .id = id; this .name = name; this .price = price; this .createDate = createDate; } @Override public String toString () { return "IPhone{" + "id=" + id + ", name='" + name + '\'' + ", price=" + price + ", createDate=" + createDate + '}' ; } public static void info () { System.out.println("Info " + "这是一部IPhone" ); } public static void info (Long id, String name) { System.out.println("Info " + "id=" + id + ", name='" + name + '\'' ); } public static IPhone create (Long id, String name) { BiFunction<Long, String, IPhone> factory = IPhone::new ; IPhone iPhone = factory.apply(id, name); System.out.println("Creating " + iPhone.toString()); return iPhone; } public static IPhone create (final Supplier<IPhone> supplier) { return supplier.get(); } public static void recover (final IPhone IPhone) { System.out.println("Recovering " + IPhone.toString()); } public void copy (final IPhone another) { System.out.println("Copying the " + another.toString()); } public void repair () { System.out.println("Repaired " + this .toString()); } }
Test类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 public class Test { public static void main (String[] args) { IPhone iPhone1 = IPhone.create(() -> new IPhone ()); IPhone iPhone2 = IPhone.create(IPhone::new ); List<IPhone> iPhones = Arrays.asList(iPhone1, iPhone2); iPhones.forEach(item -> IPhone.recover(item)); iPhones.forEach(IPhone::recover); iPhones.forEach((item) -> IPhone.create(() -> new IPhone ()).copy(item)); iPhones.forEach(IPhone.create(IPhone::new )::copy); iPhones.forEach(item -> System.out.println(item)); iPhones.forEach(System.out::println); iPhones.forEach(item -> item.repair()); iPhones.forEach(IPhone::repair); } }
构造器引用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 public class Test1 { public static void main (String[] args) { Supplier<IPhone> factory_01 = () -> new IPhone (); IPhone iPhone_01 = factory_01.get(); System.out.println(iPhone_01); Supplier<IPhone> factory_02 = IPhone::new ; IPhone iPhone_02 = factory_02.get(); System.out.println(iPhone_02); Function<Long, IPhone> factory_03 = (id) -> new IPhone (id); IPhone iPhone_03 = factory_03.apply(2020L ); System.out.println(iPhone_03); Function<Long, IPhone> factory_04 = IPhone::new ; IPhone iPhone_04 = factory_04.apply(2020L ); System.out.println(iPhone_04); BiFunction<Long, String, IPhone> factory_05 = (id, name) -> new IPhone (id, name); IPhone iPhone_05 = factory_05.apply(2020L , "IPhone 12" ); System.out.println(iPhone_05); BiFunction<Long, String, IPhone> factory_06 = IPhone::new ; IPhone iPhone_06 = factory_06.apply(2020L , "IPhone 12" ); System.out.println(iPhone_06); MyFunction<Long, String, Long, IPhone> factory_07 = (id, name, price) -> new IPhone (id, name, price); IPhone iPhone_07 = factory_07.apply(2020L , "IPhone 12" , 9999L ); System.out.println(iPhone_07); MyFunction<Long, String, Long, IPhone> factory_08 = IPhone::new ; IPhone iPhone_08 = factory_08.apply(2020L , "IPhone 12" , 9999L ); System.out.println(iPhone_08); Function<Long, Long> a = i -> i * 2 ; Function<Long, Long> b = i -> i * i; System.out.println(a.compose(b).apply(5L )); System.out.println(a.andThen(b).apply(5L )); System.out.println(Function.identity().compose(a).apply(5L )); } } @FunctionalInterface interface MyFunction <T, U, V, R> { R apply (T t, U u, V v) ; }
静态方法引用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 public class Test2 { public static void main (String[] args) { PrintFunction pf_01 = () -> IPhone.info(); pf_01.print(); PrintFunction pf_02 = IPhone::info; pf_02.print(); PrintFunction2<Long, String> pf_03 = (id, name) -> IPhone.info(id, name); pf_03.print(2020L , "IPhone 12" ); PrintFunction2<Long, String> pf_04 = IPhone::info; pf_04.print(2020L , "IPhone 12" ); PrintFunction3<Long, String, IPhone> pf_05 = (id, name) -> IPhone.create(id, name); pf_05.print(2020L , "IPhone 12" ); PrintFunction3<Long, String, IPhone> pf_06 = IPhone::create; IPhone iPhone = pf_06.print(2020L , "IPhone 12" ); } } @FunctionalInterface interface PrintFunction { void print () ; } @FunctionalInterface interface PrintFunction2 <T, U> { void print (T t, U u) ; } @FunctionalInterface interface PrintFunction3 <T, U, R> { R print (T t, U u) ; }
特定对象的方法引用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class Test3 { public static void main (String[] args) { BiFunction<Long, String, IPhone> factory_01 = (id, name) -> new IPhone (id, name); IPhone iPhone_01 = factory_01.apply(2020L , "IPhone 12" ); PrintFunction pf_01 = () -> iPhone_01.repair(); pf_01.print(); BiFunction<Long, String, IPhone> factory_02 = IPhone::new ; IPhone iPhone_02 = factory_02.apply(2020L , "IPhone 12" ); PrintFunction pf_02 = iPhone_02::repair; pf_02.print(); } }
类型注解和重复注解 类型注解
重复注解
Java8新特性-重复注解与类型注解
日期和时间 API Java 8 日期时间 API - 菜鸟
【Java8新特性】关于Java8中的日期时间API,你需要掌握这些!!
在旧版的 Java 中,日期时间 API 存在诸多问题,其中有:
非线程安全 − java.util.Date 是非线程安全的,所有的日期类都是可变的,这是Java日期类最大的问题之一。设计很差 − Java的日期/时间类的定义并不一致,在java.util和java.sql的包中都有日期类,此外用于格式化和解析的类在java.text包中定义。java.util.Date同时包含日期和时间,而java.sql.Date仅包含日期,将其纳入java.sql包并不合理。另外这两个类都有相同的名字,这本身就是一个非常糟糕的设计。时区处理麻烦 − 日期类并不提供国际化,没有时区支持,因此Java引入了java.util.Calendar和java.util.TimeZone类,但他们同样存在上述所有的问题。
Java 8 在 java.time 包下提供了很多新的 API。以下为两个比较重要的 API:
Local(本地) − 简化了日期时间的处理,不存在时区问题。Zoned(时区) − 通过制定的时区处理日期时间。
新的 java.time 包涵盖了所有处理日期,时间,日期/时间,时区,时刻(instants),过程(during)与时钟(clock)的操作。
主要方法:
now:静态方法,根据当前时间创建对象
of:静态方法,根据指定日期/时间创建对象
plusDays,plusWeeks,plusMonths,plusYears:向当前LocalDate 对象添加几天、几周、几个月、几年
minusDays,minusWeeks,minusMonths,minusYears:从当前LocalDate 对象减去几天、几周、几个月、几年
plus,minus:添加或减少一个Duration 或Period
withDayOfMonth,withDayOfYear,withMonth,withYear:将月份天数、年份天数、月份、年份修改为指定的值并返回新的LocalDate 对象
getDayOfYear:获得年份天数(1~366)
getDayOfWeek:获得星期几(返回一个DayOfWeek枚举值)
getMonth:获得月份, 返回一个Month 枚举值
getMonthValue:获得月份(1~12)
getYear:获得年份
until:获得两个日期之间的Period 对象,或者指定ChronoUnits 的数字
isBefore,isAfter:比较两个LocalDate
isLeapYear:判断是否是闰年
使用 LocalDate、 LocalTime、 LocalDateTime LocalDate、 LocalTime、 LocalDateTime 类的实例是不可变的对象,分别表示使用 ISO-8601日历系统的日期、时间、日期和时间。它们提供了简单的日期或时间,并不包含当前的时间信息。也不包含与时区相关的信息。
注: ISO-8601日历系统是国际标准化组织制定的现代公民的日期和时间的表示法
方法
描述
示例
now()
静态方法,根据当前时间创建对象
LocalDate d = LocalDate.now();
of()
静态方法,根据指定日期/时间创建 对象
LocalDate d = LocalDate.of(2020, Month.DECEMBER, 12);
plusDays, plusWeeks, plusMonths, plusYears
向当前 LocalDate 对象添加几天、 几周、 几个月、 几年
minusDays, minusWeeks, minusMonths, minusYears
从当前 LocalDate 对象减去几天、 几周、 几个月、 几年
plus, minus
添加或减少一个 Duration 或 Period
LocalDateTime LocalDateTime = LocalDateTime.now().plus(Duration.ofDays(-1));
withDayOfMonth, withDayOfYear, withMonth, withYear
将月份天数、 年份天数、 月份、 年 份 修 改 为 指 定 的 值 并 返 回 新 的 LocalDate 对象
LocalDateTime.now().withYear(2010).withMonth(9).withDayOfMonth(1);
getDayOfMonth
获得月份天数(1-31)
LocalDateTime.now().getDayOfMonth();
getDayOfYear
获得年份天数(1-366)
getDayOfWeek
获得星期几(返回一个 DayOfWeek 枚举值)
getMonth
获得月份, 返回一个 Month 枚举值
LocalDateTime.now().getMonth().get(ChronoField.MONTH_OF_YEAR);
getMonthValue
获得月份(1-12)
LocalDateTime.now().getMonthValue();
getYear
获得年份
LocalDateTime.now().getYear();
until
获得两个日期之间的 Period 对象, 或者指定 ChronoUnits 的数字
isBefore, isAfter
比较两个 LocalDate
isLeapYear
判断是否是闰年
LocalDateTime.now().toLocalDate().isLeapYear();
示例代码如下所示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 LocalDateTime localDateTime1 = LocalDateTime.now();System.out.println(localDateTime1); LocalDateTime localDateTime2 = LocalDateTime.of(2019 , 10 , 27 , 13 , 45 ,10 );System.out.println(localDateTime2); LocalDateTime localDateTime3 = localDateTime1 .plusYears(3 ) .minusMonths(3 ); System.out.println(localDateTime3); System.out.println(localDateTime1.getYear()); System.out.println(localDateTime1.getMonthValue()); System.out.println(localDateTime1.getDayOfMonth()); System.out.println(localDateTime1.getHour()); System.out.println(localDateTime1.getMinute()); System.out.println(localDateTime1.getSecond()); LocalDateTime localDateTime4 = LocalDateTime.now();System.out.println(localDateTime4); LocalDateTime localDateTime5 = localDateTime4.withDayOfMonth(10 );System.out.println(localDateTime5);
Instant 时间戳 用于“时间戳”的运算。它是以Unix元年(传统的设定为UTC时区1970年1月1日午夜时分)开始所经历的描述进行运算 。
示例代码如下所示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 Instant instant1 = Instant.now(); System.out.println(instant1); OffsetDateTime offsetDateTime = instant1.atOffset(ZoneOffset.ofHours(8 ));System.out.println(offsetDateTime); System.out.println(instant1.toEpochMilli()); Instant instant2 = Instant.ofEpochSecond(60 );System.out.println(instant2);
Duration 和 Period 详细介绍请看 Java 注释。
下面是 between 方法示例:
Duration.between:用于计算两个“时间”间隔。请看 Java 注释
Period.between:用于计算两个“日期”间隔 。请看 Java 注释
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 Instant instant_1 = Instant.now();try { Thread.sleep(1000 ); } catch (InterruptedException e) { e.printStackTrace(); } Instant instant_2 = Instant.now();Duration duration = Duration.between(instant_1, instant_2);System.out.println(duration.toMillis()); LocalTime localTime_1 = LocalTime.now();try { Thread.sleep(1000 ); } catch (InterruptedException e) { e.printStackTrace(); } LocalTime localTime_2 = LocalTime.now();System.out.println(Duration.between(localTime_1, localTime_2).toMillis()); LocalDate localDate_1 = LocalDate.of(2018 ,9 , 9 );LocalDate localDate_2 = LocalDate.now();Period period = Period.between(localDate_1, localDate_2);System.out.println(period.getYears()); System.out.println(period.getMonths()); System.out.println(period.getDays());
日期的操纵 TemporalAdjuster : 时间校正器。有时我们可能需要获取例如:将日期调整到“下个周日”等操作。
TemporalAdjusters : 该类通过静态方法提供了大量的常用 TemporalAdjuster 的实现。
例如获取下个周日,如下所示:
1 LocalDate nextSunday = LocalDate.now().with(TemporalAdjusters.next(DayOfWeek.SUNDAY));
完整的示例代码如下所示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 LocalDateTime ldt = LocalDateTime.now();System.out.println(ldt.withYear(2010 ).withMonth(9 ).withDayOfMonth(1 )); System.out.println("LocalDateTime: " + ldt.with(ChronoField.DAY_OF_YEAR, 2 )); System.out.println("LocalDateTime: " + localDateTime.with(ChronoField.valueOf("DAY_OF_YEAR" ), 2 )); System.out.println("LocalDateTime: " + ldt.with(ChronoField.MONTH_OF_YEAR, 1 )); System.out.println("LocalDateTime: " + localDateTime.with(ChronoField.valueOf("MONTH_OF_YEAR" ), 1 )); System.out.println("LocalDateTime: " + ldt.with(DayOfWeek.MONDAY)); System.out.println("LocalDateTime: " + ldt.with(DayOfWeek.of(1 ))); System.out.println("LocalDateTime: " + ldt.with(Month.JANUARY)); System.out.println("LocalDateTime: " + ldt.with(Month.of(1 ))); System.out.println("LocalDateTime: " + ldt.with(Year.parse("2012" ))); System.out.println("LocalDateTime: " + ldt.with(Year.of(2012 ))); LocalDateTime localDateTime1 = LocalDateTime.now();System.out.println(localDateTime1); System.out.println(localDateTime1.with(TemporalAdjusters.firstDayOfMonth())); System.out.println(localDateTime1.with(TemporalAdjusters.next(DayOfWeek.SUNDAY))); LocalDateTime localDateTime2 = localDateTime1.with(l -> { LocalDateTime localDateTime = (LocalDateTime) l; DayOfWeek dayOfWeek = localDateTime.getDayOfWeek(); if (dayOfWeek.equals(DayOfWeek.FRIDAY)) { return localDateTime.plusDays(3 ); } else if (dayOfWeek.equals(DayOfWeek.SATURDAY)) { return localDateTime.plusDays(2 ); } else { return localDateTime.plusDays(1 ); } }); System.out.println(localDateTime2);
解析与格式化 java.time.format.DateTimeFormatter 类:该类提供了三种格式化方法:
预定义的标准格式
语言环境相关的格式
自定义的格式
示例代码如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 LocalDateTime localDateTime = LocalDateTime.now();DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss" , Locale.getDefault());String dateTimeToStr_1 = localDateTime.format(DateTimeFormatter.ISO_DATE); String dateTimeToStr_2 = localDateTime.format(dateTimeFormatter); String dateTimeToStr_3 = dateTimeFormatter.format(localDateTime); LocalDateTime strToDateTime_0 = LocalDateTime.parse("2008-08-08T08:00:00.999999999" );LocalDateTime strToDateTime_1 = LocalDateTime.parse(dateTimeToStr_1, dateTimeFormatter); LocalDateTime strToDateTime_2 = LocalDateTime.parse("2008-08-08 08:00:00" , dateTimeFormatter); LocalDate date_0 = LocalDate.parse("2012-09-08" ); LocalDate date_1 = LocalDate.parse("2012-09-08T13:00:20.776" , DateTimeFormatter.ISO_LOCAL_DATE_TIME); LocalDate date_2 = LocalDate.parse("2012-09-08" , DateTimeFormatter.ISO_LOCAL_DATE); LocalDate date_3 = LocalDate.parse("2012-09-08" , DateTimeFormatter.ISO_DATE); LocalDate date_4 = LocalDate.parse("2012-252" , DateTimeFormatter.ISO_ORDINAL_DATE); LocalDate date_5 = LocalDate.parse("2012-W36-6" , DateTimeFormatter.ISO_WEEK_DATE); LocalDate date_6 = LocalDate.parse("20120908" , DateTimeFormatter.BASIC_ISO_DATE); LocalDate date_7 = LocalDate.parse("2012-09-08+08:00" , DateTimeFormatter.ISO_OFFSET_DATE); LocalTime time_0 = LocalTime.parse("08:00:00.999999999" ); LocalTime time_1 = LocalTime.parse("2008-08-08 08:00:00" , dateTimeFormatter);
时区的处理 Java8 中加入了对时区的支持,带时区的时间为:ZonedDateTime。
其中每个时区都对应着 ID,地区ID都为 “{区域}/{城市}”的格式,例如 : Asia/Shanghai 等。
ZoneId:该类中包含了所有的时区信息
getAvailableZoneIds() : 可以获取所有时区时区信息
of(id) : 用指定的时区信息获取 ZoneId 对象
示例代码如下所示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 Set<String> set = ZoneId.getAvailableZoneIds(); System.out.println(set); LocalDateTime ldt1 = LocalDateTime.now(Clock.systemDefaultZone());LocalDateTime ldt2 = LocalDateTime.now(ZoneId.systemDefault());LocalDateTime ldt3 = LocalDateTime.now(ZoneId.of("Australia/Sydney" ));System.out.println(ldt3); LocalDateTime ldt5 = LocalDateTime.now();ZonedDateTime zdt1 = ldt5.atZone(ZoneId.of("Africa/Nairobi" ));System.out.println(zdt1);
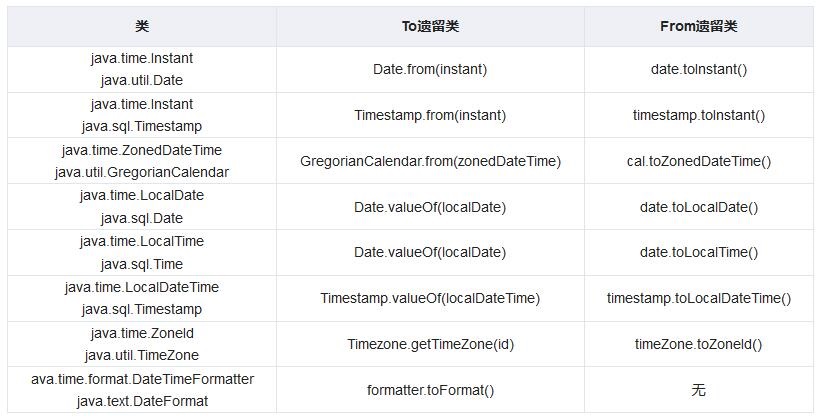
与传统日期处理的转换
Optional 类 什么是Optional类 Optional 类是一个可以为null的容器对象。如果值存在则isPresent()方法会返回true,调用get()方法会返回该对象。
Optional 是个容器:它可以保存类型T的值,或者仅仅保存null。Optional提供很多有用的方法,这样我们就不用显式进行空值检测。
Optional 类的引入很好的解决空指针异常。
Optional类常用方法:
public static <T> Optional <T> empty () : 返回空的 Optional 实例。
public boolean isPresent () : 如果存在值,则返回 true,否则返回 false。
public void ifPresent (Consumer<? super T> consumer) : 如果值存在则使用该值调用 consumer , 否则不做任何事情。
public T get () : 如果此 Optional 中存在值,则返回该值,否则抛出 NoSuchElementException。
public T orElse (T other) : 返回值 (如果存在),否则返回 other。
public T orElseGet (Supplier<? extends T> other) : 返回值 (如果存在),否则调用 other 并返回该调用的结果。
public <X extends Throwable> T orElseThrow (Supplier<? extends X> exceptionSupplier) throws X : 返回值 (如果存在),否则 supplier 抛出异常。
public static <T> Optional <T> of (T value) : 返回一个指定非null值的 Optional。
public static <T> Optional <T> ofNullable (T value) : 如果为非空,返回 Optional 描述的指定值,否则返回空的 Optional。
public <U> Optional<U> map (Function<? super T, ? extends U> mapper) : 如果此 Optional 有值,则对其执行调用映射函数得到返回值,如果映射器 (mapper) 返回值不为 null,则创建包含映射器 (mapper) 返回值的新Optional 作为map方法返回值,否则返回空Optional。如果此 Optional 无值,返回空Optional。
public <U> Optional<U> flatMap (Function<? super T, Optional<U>> mapper) : 与 map 类似,但要求 mapper 返回值必须是 Optional。如果值存在,返回基于映射器 (mapper) 的返回值,否则返回一个空的Optional。
public Optional<T> filter (Predicate<? super T> predicate) : 如果值存在,并且该值与给定 predicate 匹配,则返回描述该值的 Optional (当前 Optional 对象,即 this),否则返回空的 Optional。
重写 Object 的方法:
public boolean equals (Object obj) :
public int hashCode () :
public String toString () :
Optional类示例 创建Optional类 (1)使用empty()方法创建一个空的Optional对象:
1 Optional<String> empty = Optional.empty();
(2)使用of()方法创建Optional对象:
1 2 3 String name = "binghe" ;Optional<String> opt = Optional.of(name); assertEquals("Optional[binghe]" , opt.toString());
传递给of()的值不可以为空,否则会抛出空指针异常。例如,下面的程序会抛出空指针异常。
1 2 String name = null ;Optional<String> opt = Optional.of(name);
如果我们需要传递一些空值,那我们可以使用下面的示例所示。
1 2 String name = null ;Optional<String> opt = Optional.ofNullable(name);
使用ofNullable()方法,则当传递进去一个空值时,不会抛出异常,而只是返回一个空的Optional对象,如同我们用Optional.empty()方法一样。
isPresent 我们可以使用这个isPresent()方法检查一个Optional对象中是否有值,只有值非空才返回true。
1 2 3 4 5 Optional<String> opt = Optional.of("binghe" ); assertTrue(opt.isPresent()); opt = Optional.ofNullable(null ); assertFalse(opt.isPresent());
在Java8之前,我们一般使用如下方式来检查空值。
1 2 3 if (name != null ){ System.out.println(name.length); }
在Java8中,我们就可以使用如下方式来检查空值了。
1 2 Optional<String> opt = Optional.of("binghe" ); opt.ifPresent(name -> System.out.println(name.length()));
get get()方法表示从Optional对象中获取值。
1 2 3 Optional<String> opt = Optional.of("binghe" ); String name = opt.get();assertEquals("binghe" , name);
使用get()方法也可以返回被包裹着的值。但是值必须存在。当值不存在时,会抛出一个NoSuchElementException异常。
1 2 Optional<String> opt = Optional.ofNullable(null ); String name = opt.get();
orElse和orElseGet (1)orElse
orElse()方法用来返回Optional对象中的默认值,它被传入一个“默认参数‘。如果Optional对象中有值,则返回它,否则返回传入的“默认参数”。
1 2 3 String nullName = null ;String name = Optional.ofNullable(nullName).orElse("binghe" );assertEquals("binghe" , name);
(2)orElseGet:推荐使用
与orElse()方法类似,但是这个函数不接收一个“默认参数”,而是一个函数接口。
1 2 3 String nullName = null ;String name = Optional.ofNullable(nullName).orElseGet(() -> "binghe" );assertEquals("binghe" , name);
(3)二者有什么区别?
要想理解二者的区别,首先让我们创建一个无参且返回定值的方法。
1 2 3 4 public String getDefaultName () { System.out.println("Getting Default Name" ); return "binghe" ; }
接下来,进行两个测试看看两个方法到底有什么区别。
1 2 3 4 5 6 7 8 String text; System.out.println("Using orElseGet:" ); String defaultText = Optional.ofNullable(text).orElseGet(this ::getDefaultName);assertEquals("binghe" , defaultText); System.out.println("Using orElse:" ); defaultText = Optional.ofNullable(text).orElse(getDefaultName()); assertEquals("binghe" , defaultText);
在这里示例中,我们的Optional对象中包含的都是一个空值,让我们看看程序执行结果:
1 2 3 4 Using orElseGet: Getting default name... Using orElse: Getting default name...
两个Optional对象中都不存在value,因此执行结果相同。
那么,当Optional对象中存在数据会发生什么呢?我们一起来验证下。
1 2 3 4 5 6 7 8 9 String name = "binghe001" ;System.out.println("Using orElseGet:" ); String defaultName = Optional.ofNullable(name).orElseGet(this ::getDefaultName);assertEquals("binghe001" , defaultName); System.out.println("Using orElse:" ); defaultName = Optional.ofNullable(name).orElse(getDefaultName()); assertEquals("binghe001" , defaultName);
运行结果如下所示。
1 2 3 Using orElseGet: Using orElse: Getting default name...
可以看到,当使用orElseGet()方法时,getDefaultName()方法并不执行,因为Optional中含有值,而使用orElse时则照常执行。所以可以看到,当值存在时,orElse相比于orElseGet,多创建了一个对象。如果创建对象时,存在网络交互,那系统资源的开销就比较大了,这是需要我们注意的一个地方。
orElseThrow orElseThrow()方法当遇到一个不存在的值的时候,并不返回一个默认值,而是抛出异常。
1 2 String nullName = null ;String name = Optional.ofNullable(nullName).orElseThrow(IllegalArgumentException::new );
map 如果有值对其处理,并返回处理后的Optional,否则返回 Optional.empty()。
1 2 3 4 5 6 7 List<String> names = Arrays.asList("binghe001" , "binghe002" , "" , "binghe003" , "" , "binghe004" ); Optional<List<String>> listOptional = Optional.of(names); int size = listOptional .map(List::size) .orElse(0 ); assertEquals(6 , size);
在这个例子中,我们使用一个List集合封装了一些字符串,然后再把这个List使用Optional封装起来,对其map(),获取List集合的长度。map()返回的结果也被封装在一个Optional对象中,这里当值不存在的时候,我们会默认返回0。如下我们获取一个字符串的长度。
1 2 3 4 5 6 7 String name = "binghe" ;Optional<String> nameOptional = Optional.of(name); int len = nameOptional .map(String::length) .orElse(0 ); assertEquals(6 , len);
我们也可以将map()方法与filter()方法结合使用,如下所示。
1 2 3 4 5 6 7 8 9 10 11 String password = " password " ;Optional<String> passOpt = Optional.of(password); boolean correctPassword = passOpt.filter( pass -> "password" .equals(pass)).isPresent(); assertFalse(correctPassword); correctPassword = passOpt .map(String::trim) .filter(pass -> "password" .equals(pass) .isPresent(); assertTrue(correctPassword);
上述代码的含义就是对密码进行验证,查看密码是否为指定的值。
flatMap 与 map 类似,要求返回值必须是Optional。
假设我们现在有一个Person类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 @Data @Builder @ToString @NoArgsConstructor @AllArgsConstructor public class Person { private String name; private int age; private String password; public Person (String name, int age) { this .name = name; this .age = age; } public Optional<String> getName () { return Optional.ofNullable(name); } public Optional<Integer> getAge () { return Optional.ofNullable(age); } public Optional<String> getPassword () { return Optional.ofNullable(password); } }
接下来,我们可以将Person封装到Optional中,并进行测试,如下所示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Person person = new Person ("binghe" , 18 );Optional<Person> personOptional = Optional.of(person); Optional<Optional<String>> nameOptionalWrapper = personOptional.map(Person::getName); Optional<String> nameOptional = nameOptionalWrapper.orElseThrow(IllegalArgumentException::new ); String name1 = nameOptional.orElse("" );assertEquals("binghe" , name1); String name2 = personOptional.flatMap(Person::getName).orElse("" );assertEquals("binghe" , name2);
filter 接收一个函数式接口,当匹配接口时,则返回当前Optional对象,否则返回一个空的Optional对象。
1 2 3 4 5 6 String name = "binghe" ;Optional<String> nameOptional = Optional.of(name); boolean isBinghe = nameOptional.filter(n -> "binghe" .equals(name)).isPresent();assertTrue(isBinghe); boolean isBinghe001 = nameOptional.filter(n -> "binghe001" .equals(name)).isPresent();assertFalse(isBinghe001);
使用filter()方法会过滤掉我们不需要的元素。
接下来,我们再来看一例示例,例如目前有一个Person类,如下所示。
1 2 3 4 5 6 7 public class Person { private int age; public Person (int age) { this .age = age; } }
例如,我们需要过滤出年龄在25岁到35岁之前的人群,那在Java8之前我们需要创建一个如下的方法来检测每个人的年龄范围是否在25岁到35岁之前。
1 2 3 4 5 6 7 public boolean filterPerson (Peron person) { boolean isInRange = false ; if (person != null && person.getAge() >= 25 && person.getAge() <= 35 ){ isInRange = true ; } return isInRange; }
看上去就挺麻烦的,我们可以使用如下的方式进行测试。
1 2 3 4 5 assertTrue(filterPerson(new Peron (18 ))); assertFalse(filterPerson(new Peron (29 ))); assertFalse(filterPerson(new Peron (16 ))); assertFalse(filterPerson(new Peron (34 ))); assertFalse(filterPerson(null ));
如果使用Optional,效果如何呢?
1 2 3 4 5 6 7 public boolean filterPersonByOptional (Peron person) { return Optional.ofNullable(person) .map(Peron::getAge) .filter(p -> p >= 25 ) .filter(p -> p <= 35 ) .isPresent(); }
使用Optional看上去就清爽多了,这里,map()仅仅是将一个值转换为另一个值,并且这个操作并不会改变原来的值。
Stream API Java 8 Stream - 菜鸟
概述 Java 8 API添加了一个新的抽象称为流Stream,可以让你以一种声明的方式处理数据 。
Stream 使用一种类似用 SQL 语句从数据库查询数据的直观方式来提供一种对 Java 集合 运算和表达的高阶抽象 。
Stream API可以极大提高Java程序员的生产力,让程序员写出高效率、干净、简洁的代码。
什么是 Stream? Stream(流)是一个来自数据源的元素队列并支持聚合操作
元素是特定类型的对象,形成一个队列。 Java中的Stream并不会存储元素,而是按需计算。
数据源 流的来源。 可以是集合,数组,I/O channel, 产生器 generator 等。聚合操作 类似 SQL 语句一样的操作, 比如 filter, map, reduce, find, match, sorted 等。
和以前的 Collection 操作不同, Stream 操作还有两个基础的特征
流水线 (Pipeline) :中间操作都会返回流对象本身。 这样多个操作可以串联成一个管道, 如同流式风格(fluent style)。 这样做可以对操作进行优化, 比如延迟执行(laziness)和短路( short-circuiting)。内部迭代 :以前对集合遍历都是通过Iterator或者For-Each的方式, 显式的在集合外部进行迭代, 这叫做外部迭代。 Stream提供了内部迭代的方式, 通过访问者模式(Visitor)实现。
注意:
①Stream 自己不会存储元素。
②Stream 不会改变源对象。相反,他们会返回一个持有结果的新Stream。
③Stream 操作是延迟执行的。这意味着他们会等到需要结果的时候才执行。
Stream操作步骤 将要处理的元素集合看作一种流, 流在管道中传输, 并且可以在管道的节点上进行处理, 比如筛选, 排序,聚合等。
元素流在管道中经过中间操作(intermediate operation)的处理,最后由终端操作(terminal operation)得到前面处理的结果。
1 2 3 +--------------------+ +------+ +------+ +---+ +-------+ | stream of elements +-----> |filter+-> |sorted+-> |map+-> |collect| +--------------------+ +------+ +------+ +---+ +-------+
步骤一、创建 Stream
一个数据源(如: 集合、数组), 获取一个流。
步骤二、中间操作
一个中间操作链,对数据源的数据进行处理。
步骤三、终止操作(终端操作)
一个终止操作,执行中间操作链,并产生结果 。
以上步骤转换为 Java 代码为:
1 2 3 4 5 6 List<Integer> transactionsIds = widgets.stream() .filter(b -> b.getColor() == RED) .sorted((x,y) -> x.getWeight() - y.getWeight()) .mapToInt(Widget::getWeight) .sum();
如何创建Stream流? Collection接口的两个default方法 在 Java 8 中, 单列集合Collection接口有两个方法来生成集合流 。示例:
1 2 3 4 5 List<String> list = new ArrayList <>(); list.stream(); list.parallelStream();
Arrays工具类的静态方法stream() Java8 中的 Arrays类的静态方法 stream() 可以获取数组流 ,还提供了多种形式的重载。示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 public class Test { public static void main (String[] args) { int [] arrayInt = new int []{1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 }; IntStream intStream = Arrays.stream(arrayInt); long [] arrayLong = new long []{1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 }; LongStream longStream = Arrays.stream(arrayLong); double [] arrayDouble = new double []{1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 }; DoubleStream doubleStream = Arrays.stream(arrayDouble); Object[] arrayObject = new Object []{"1" , "2" , "3" , "4" , "5" , "6" , "7" , "8" , "9" }; Stream<Object> stream = Arrays.stream(arrayObject); arrayObject = Arrays.stream(arrayObject).toArray(); arrayObject = Arrays.stream(arrayObject).toArray(Object[]::new ); for (int i = 0 ; i < arrayObject.length; i++) { if (i == 0 ) { System.out.print("[" ); } if (i == arrayObject.length - 1 ) { System.out.print(arrayObject[i]); System.out.println("]" ); continue ; } System.out.print(arrayObject[i] + ", " ); } List list = Arrays.stream(arrayObject).collect(Collectors.toList()); System.out.println(list); Set set = Arrays.stream(arrayObject).collect(Collectors.toSet()); System.out.println(set); } }
Stream类的静态方法of() 在Stream类中,提供了两个of()方法用以获取流,一个参数是泛型,另一个参数是可变泛型。
同理:IntStream.of、LongStream.of、DoubleStream.of
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class Test { public static void main (String[] args) { List<String> strList = Arrays.asList("a" , "b" , "c" ); Stream<List<String>> arrayStream1 = Stream.of(strList); arrayStream1.forEach(System.out::println); Stream<String> arrayStream2 = Stream.of("a" , "b" , "c" ); arrayStream2.forEach(System.out::println); IntStream intStream = IntStream.of(1 , 2 , 3 , 4 , 5 ); intStream.boxed().forEach(System.out::println); } }
Random类 更多重载方法见源码。
1 2 3 4 5 6 7 8 9 10 Random random = new Random ();IntStream intStream = random.ints(5 , 1 , 5 );intStream.forEach(System.out::println); LongStream longStream = random.longs(5 , 1 , 5 );longStream.forEach(System.out::println); DoubleStream doubleStream = random.doubles(5 , 1.0 , 5.0 );doubleStream.forEach(System.out::println);
创建无限流 Stream类 可以使用静态方法 Stream.iterate() 和Stream.generate(), 创建无限流。
1 2 3 4 5 6 7 Stream<Integer> stream1 = Stream.iterate(2 , x -> x + 2 ); stream1.limit(5 ).forEach(System.out::println); Stream<Double> stream2 = Stream.generate(() -> Math.random()); stream2.limit(5 ).forEach(System.out::println);
Random类 1 2 Random random = new Random ();random.ints().forEach(System.out::println);
创建空流 1 2 3 4 Stream<String> empty1 = Stream.empty(); Stream<Integer> empty2 = Stream.empty(); Stream<Long> empty3 = Stream.empty(); Stream<Double> empty4 = Stream.empty();
并行流与串行流 什么是并行流? 简单来说,并行流就是把一个内容分成多个数据块,并用不同的线程分别处理每个数据块的流。
Java 8 中将并行进行了优化,我们可以很容易的对数据进行并行操作。
Stream API 可以通过 BaseStream 类的 parallel() 和 sequential() 方法在并行流与串行流之间进行切换 。
1 2 3 4 List<String> list = Arrays.asList("aaa" , "bbb" , "ccc" , "ddd" ); list.stream(); list.parallelStream(); list.stream().parallel().sequential().isParallel();
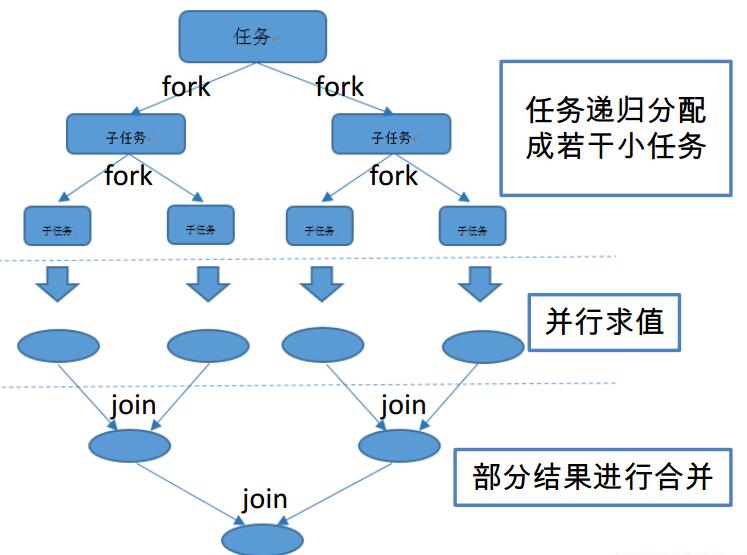
Fork/Join 框架 推荐链接: Java并发编程(07):Fork/Join框架机制详解
Fork/Join 框架: 就是在必要的情况下,将一个大任务,进行拆分(fork)成若干个小任务(拆到不可再拆时),再将一个个的小任务运算的结果进行 join 汇总 。
Fork/Join 框架与传统线程池有啥区别? 采用 “工作窃取”模式(work-stealing):
当执行新的任务时它可以将其拆分成更小的任务执行,并将小任务加到线程队列中,然后再从一个随机线程的队列中偷一个并把它放在自己的队列中。
相对于一般的线程池实现,fork/join框架的优势体现在对其中包含的任务的处理方式上。在一般的线程池中,如果一个线程正在执行的任务由于某些原因无法继续运行,那么该线程会处于等待状态。而在fork/join框架的实现中,如果某个子任务由于等待另外一个子任务的完成而无法继续运行。那么处理该子问题的线程会主动寻找其他尚未运行的子任务来执行。这种方式减少了线程的等待时间,提高了程序的性能。
Fork/Join框架实例 了解了Fork/Join框架的原理之后,我们就来手动写一个使用Fork/Join框架实现累加和的示例程序,以帮助理解Fork/Join框架。好好体会下Fork/Join框架的强大。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 @Slf4j public class ForkJoinTaskExample extends RecursiveTask <Long> { public static final long startValue = 0 ; public static final long endValue = 600000000L ; public static long threshold; private long start; private long end; public ForkJoinTaskExample (long start, long end) { this .start = start; this .end = end; threshold = endValue / 6 ; } @Override protected Long compute () { long sum = 0 ; boolean canCompute = (end - start) <= threshold; if (canCompute) { for (long i = start; i <= end; i++) { sum += i; } } else { long middle = (start + end) / 2 ; ForkJoinTaskExample leftTask = new ForkJoinTaskExample (start, middle); ForkJoinTaskExample rightTask = new ForkJoinTaskExample (middle + 1 , end); leftTask.fork(); rightTask.fork(); long leftResult = leftTask.join(); long rightResult = rightTask.join(); sum = leftResult + rightResult; } return sum; } public static void main (String[] args) { long startTime = System.nanoTime(); ForkJoinPool forkjoinPool = new ForkJoinPool (); ForkJoinTaskExample task = new ForkJoinTaskExample (startValue, endValue); Future<Long> result = forkjoinPool.submit(task); try { log.info("result:{}" , result.get()); log.info("---- Fork/Join 框架耗时:\t" + (System.nanoTime() - startTime)); } catch (Exception e) { log.error("exception" , e); } long startTime2 = System.nanoTime(); long sum2 = 0 ; for (long i = startValue; i <= endValue; i++) { sum2 += i; } log.info("result:{}" , sum2); log.info("---- 普通 for 循环耗时:\t" + (System.nanoTime() - startTime2)); long startTime3 = System.nanoTime(); long sum3 = LongStream.rangeClosed(startValue, endValue).parallel().reduce(0 , Long::sum); log.info("result:{}" , sum3); log.info("---- stream 流耗时:\t\t" + (System.nanoTime() - startTime3)); } }
统计 以下是已有的三个于收集统计信息(例如计数,最小值,最大值,总和和平均值)的摘要:
IntSummaryStatistics
LongSummaryStatistics
DoubleSummaryStatistics
可以由 IntStream、LongStream、DoubleStream 的 summaryStatistics() 方法获得。
也可以在使用 Stream.collect(Collector<? super T, A, R> collector) 方法时,传入 Collectors 的 summarizingInt 、summarizingLong、summingDouble 方法,以获取统计摘要。示例:
1 DoubleSummaryStatistics dss = listEmployees.stream().collect(Collectors.summarizingDouble(Employee::getSalary));
完整示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 List<Integer> numbers = Arrays.asList(3 , 2 , 2 , 3 , 7 , 3 , 5 ); System.out.println("-----------------------------------------------" ); System.out.println((ArrayList) numbers.stream().mapToInt(x -> x).collect(ArrayList::new , (list1, e) -> list1.add(e), (list1, list2) -> list1.addAll(list2))); System.out.println(numbers.stream().mapToInt(x -> x).boxed().collect(Collectors.toList())); System.out.println(numbers.stream().flatMapToDouble(x -> DoubleStream.of(x)).boxed().collect(Collectors.toList())); System.out.println("-----------------------------------------------" ); IntSummaryStatistics stats_1 = numbers.stream().mapToInt((x) -> x).summaryStatistics();System.out.println("列表中最大的数 : " + stats_1.getMax()); System.out.println("列表中最小的数 : " + stats_1.getMin()); System.out.println("所有数之和 : " + stats_1.getSum()); System.out.println("平均数 : " + stats_1.getAverage()); System.out.println("计数 : " + stats_1.getCount()); System.out.println("-----------------------------------------------" ); IntSummaryStatistics stats_2 = numbers.stream().flatMapToInt(x -> IntStream.of(x)).summaryStatistics();System.out.println("列表中最大的数 : " + stats_2.getMax()); System.out.println("列表中最小的数 : " + stats_2.getMin()); System.out.println("所有数之和 : " + stats_2.getSum()); System.out.println("平均数 : " + stats_2.getAverage()); System.out.println("计数 : " + stats_2.getCount()); System.out.println("-----------------------------------------------" );
Stream的中间操作 多个中间操作可以连接起来形成一个流水线,除非流水线上触发终止操作,否则中间操作不会执行任何的处理!而在终止操作时一次性全部处理,称为“惰性求值” 。 Stream的中间操作是不会有任何结果数据输出的。
Stream的中间操作在整体上可以分为:筛选与切片、映射、排序。
筛选与切片 筛选和切片相关操作:
方法
描述
filter(Predicate p)
接收Lambda表达式,从流中排除某些元素
distinct()
筛选,通过流所生成元素的 hashCode() 和 equals() 去 除重复元素
limit(long maxSize)
截断流,使其元素不超过给定数量
skip(long n)
跳过元素,返回一个扔掉了前 n 个元素的流。若流中元素 不足 n 个,则返回一个空流。与 limit(n) 互补
接下来,我们列举几个简单的示例,以便加深理解。
为了更好的测试程序,先构造一个对象数组,如下。
1 2 3 4 5 6 7 protected static List<Employee> listEmployee = Arrays.asList( new Employee ("张三" , 18 , 9999.99 ), new Employee ("李四" , 38 , 5555.55 ), new Employee ("王五" , 60 , 6666.66 ), new Employee ("赵六" , 8 , 7777.77 ), new Employee ("田七" , 58 , 3333.33 ) );
Employee类的定义如下。
1 2 3 4 5 6 7 8 9 10 11 @Data @Builder @ToString @NoArgsConstructor @AllArgsConstructor class Employee implements Serializable { private static final long serialVersionUID = -9079722457749166858 L; private String name; private Integer age; private Double salary; }
filter filter 方法用于通过设置的条件过滤出元素。以下代码片段使用 filter 方法过滤出空字符串:
1 2 3 4 5 List<String>strings = Arrays.asList("abc" , "" , "bc" , "efg" , "abcd" ,"" , "jkl" ); List<String> strings2 = strings.stream().filter(t -> t.contains("a" )).collect(Collectors.toList()); long count = strings.stream().filter(string -> string.isEmpty()).count();
limit limit 方法返回由该流的元素组成的流,其长度被截断。
1 2 3 4 5 6 Random random = new Random ();random.ints().limit(10 ).forEach(System.out::println); List<String> strings = Arrays.asList("abc" , "" , "bc" , "efg" , "abcd" ,"" , "jkl" ); List<String> strings2 = strings.stream().limit(3 ).collect(Collectors.toList());
skip skip 方法丢弃流的前 n 个元素,返回由其余元素组成的流。如果此流包含少于 n 个元素,则将返回空流。
1 2 listEmployee.stream().skip(3 ).forEach(System.out::println);
distinct distinct 方法通过流所生成元素的 hashCode() 和 equals() 去除重复元素。
1 System.out.println(listEmployee.stream().distinct().collect(Collectors.toList()));
注意:distinct 需要实体中重写 hashCode() 和 equals() 方法才可以使用。
映射 映射相关操作:
方法
返回类型
描述
map(Function f)
Stream
接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 Stream。
mapToDouble(ToDoubleFunction f)
DoubleStream
接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 DoubleStream。
mapToInt(ToIntFunction f)
IntStream
接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 IntStream。
mapToLong(ToLongFunction f)
LongStream
接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 LongStream。
flatMap(Function f)
Stream
接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个 Stream。
flatMapToDouble(Function f)
DoubleStream
接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个 DoubleStream。
flatMapToInt(Function f)
IntStream
接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个 IntStream。
flatMapToLong(Function f)
LongStream
接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个 LongStream。
map map 方法返回一个流,该流包括将给定函数应用于此流的元素的结果。
1 2 3 4 5 6 7 8 9 10 11 12 List<Integer> numbers = Arrays.asList(3 , 2 , 2 , 3 , 7 , 3 , 5 ); List<Integer> squaresList = numbers.stream().map(i -> i * i).distinct().collect(Collectors.toList()); System.out.println(squaresList); List<String> listStr = Arrays.asList("aaa" , "bbb" , "ccc" , "ddd" ); listStr.stream().map((e) -> e.toUpperCase()).forEach(System.out::printf); List<String> names = listEmployee.stream().map(Employee::getName).collect(Collectors.toList()); System.out.println(names);
flatMap 返回一个流,将流中的 n 个元素,通过映射函数处理得到 n 个映射流,然后将每个映射流的内容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public class Test { public static void main (String[] args) { List<String> list = Arrays.asList("aaa" , "bbb" , "ccc" , "ddd" ); list.stream().flatMap(Test::filterCharacter).forEach(System.out::println); list.stream().map(Test::filterCharacter).forEach((e) -> { e.forEach(System.out::println); }); } public static Stream<String> filterCharacter (String str) { List<String> list = new ArrayList <>(); list.add(str); return list.stream(); } }
其实 map 方法就相当于 Collection 的 add 方法,如果 add 的是个集合得话就会变成二维数组,而 flatMap 的话就相当于 Collections.addAll() 方法,参数如果是集合得话,只是将2个集合合并,而不是变成二维数组。
排序 排序相关操作:
方法
描述
sorted()
产生一个新流,其中按自然顺序排序
sorted(Comparator comp)
产生一个新流,其中按比较器顺序排序
从上述表格可以看出:sorted有两种方法,一种是不传任何参数,叫自然排序 ,还有一种需要传Comparator 接口参数,叫做定制排序 。
sorted sorted 方法用于对流进行排序。以下代码片段使用 sorted 方法对输出的 10 个随机数进行排序:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 Random random = new Random ();List<Integer> list = random.ints().limit(10 ).sorted().boxed().collect(Collectors.toList()); list.forEach(System.out::println); List<String> strings = Arrays.asList("abc" , "" , "bc" , "efg" , "abcd" , "" , "ba" , "jkl" ); strings = strings.stream().sorted(String::compareTo).collect(Collectors.toList()); listEmployee.stream().sorted((e1, e2) -> { if (e1.getAge().equals(e2.getAge())) { return 0 ; } else if (e1.getAge() > e2.getAge()) { return 1 ; } else { return -1 ; } }).forEach((e) -> System.out.println(e.getAge()));
Stream的终止操作 终端操作会从流的流水线生成结果。其结果可以是任何不是流的值,例如: List、 Integer、Double、String等等,甚至是 void 。
为了更好的测试程序,先构造一个对象数组,如下。
1 2 3 4 5 6 7 protected static List<Employee> listEmployees = Arrays.asList( new Employee ("张三" , 18 , 9999.99 , Employee.Stauts.SLEEPING), new Employee ("李四" , 38 , 5555.55 , Employee.Stauts.WORKING), new Employee ("王五" , 60 , 6666.66 , Employee.Stauts.WORKING), new Employee ("赵六" , 8 , 7777.77 , Employee.Stauts.SLEEPING), new Employee ("田七" , 58 , 8888.88 , Employee.Stauts.VOCATION) );
Employee类的定义如下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @Data @Builder @ToString @NoArgsConstructor @AllArgsConstructor class Employee implements Serializable { private static final long serialVersionUID = -9079722457749166858L ; private String name; private Integer age; private Double salary; private Stauts stauts; public enum Stauts { WORKING, SLEEPING, VOCATION } }
forEach
方法
描述
forEach(Consumer c)
内部迭代(使用 Collection 接口需要用户去做迭代,称为外部迭代。相反, Stream API 使用内部迭代)
为此流的每个元素执行一个动作 (内部迭代流中的每个数据)。
此操作的行为是明确不确定的。对于并行流管道,此操作不能保证遵守流遇到的顺序,保证顺序会牺牲并行的好处。如果操作访问共享状态(比如:线程安全、共享变量),请做好所需的同步, parallelStream线程安全问题
1 2 3 4 5 6 7 8 9 10 11 void forEach (Consumer<? super T> action) ;listEmployees.stream().forEach(System.out::println); List<String> strings = Arrays.asList("abc" , "" , "bc" , "efg" , "abcd" , "" , "jkl" ); strings.stream().forEach(t -> System.out.println(t)); strings.stream().forEach(System.out::println); Random random = new Random ();random.ints().limit(10 ).forEach(System.out::println);
查找与匹配 查找与匹配相关操作:
方法
描述
allMatch(Predicate p)
检查是否匹配所有元素
anyMatch(Predicate p)
检查是否至少匹配一个元素
noneMatch(Predicate p)
检查是否没有匹配所有元素
findFirst()
返回第一个元素
findAny()
返回当前流中的任意元素
count()
返回流中元素总数
max(Comparator c)
返回流中最大值
min(Comparator c)
返回流中最小值
allMatch 返回此流的所有元素是否与提供的 Predicate 匹配。如果流中的所有元素都与提供的 Predicate 匹配,或者流为空,返回 true。函数式接口 Predicate 中可选择要处理的元素。
注意:使用allMatch()方法时,只有所有的元素都匹配条件时 (即 Predicate 都返回true),allMatch()方法才会返回true。
1 2 3 4 5 6 7 8 boolean match = listEmployees.stream().allMatch((e) -> { boolean boo = true ; if (e.getName().equals("李四" )) { boo = Employee.Stauts.SLEEPING.equals(e.getStauts()); } return boo; }); System.out.println(match);
anyMatch 返回此流的任何元素是否与提供的 Predicate 匹配。如果流中无任何元素与提供的 Predicate 匹配,或者流为空,返回 false。函数式接口 Predicate 中可选择要处理的元素。
注意:使用anyMatch()方法时,只要有一个元素匹配条件 (即 Predicate 返回true),anyMatch()方法就会返回true。
1 2 3 4 5 6 7 8 boolean match = listEmployees.stream().anyMatch((e) -> { boolean boo = false ; if (e.getName().equals("李四" )) { boo = Employee.Stauts.WORKING.equals(e.getStauts()); } return boo; }); System.out.println(match);
noneMatch 返回此流中是否没有元素与提供的 Predicate 匹配。如果流中没有元素与提供的 Predicate 匹配,或者流为空,返回 true。函数式接口 Predicate 中可选择要处理的元素。
注意:使用noneMatch()方法时,只有所有的元素都不匹配条件时 (即 Predicate 都返回false),noneMatch()方法才会返回true。
1 2 3 4 5 6 7 8 boolean match = listEmployees.stream().noneMatch((e) -> { boolean boo = false ; if (e.getName().equals("李四" )) { boo = Employee.Stauts.SLEEPING.equals(e.getStauts()); } return boo; }); System.out.println(match);
findFirst 返回描述此流的第一个元素的 Optional,如果流为空,则返回空的 Optional。如果流没有遇到顺序,则可以返回任何元素。
1 2 3 Optional<Employee> opt = listEmployees.stream().findFirst(); System.out.println(opt.isPresent()); System.out.println(opt.get());
findAny 返回描述流中任意一个元素的 Optional,如果流为空,则返回空的{@code Optional}。
串行操作:与 findFirst() 返回值相同。
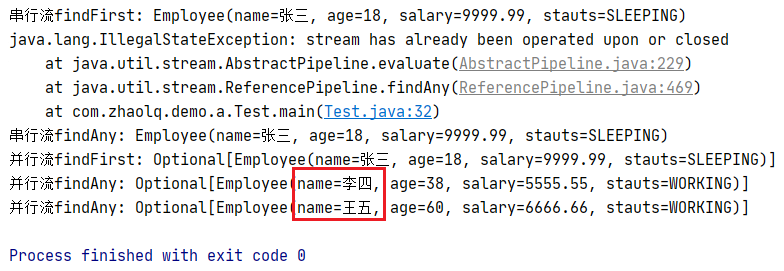
并行操作:此操作的行为是不确定的,可以自由选择流中的任何元素。这是为了在并行操作中获得最佳性能。代价是对同一源的多次调用可能不会返回相同的结果。(如果需要稳定的结果,请改用{@link #findFirst()}。)
1 2 3 4 5 6 7 8 9 10 11 12 13 Stream<Employee> stream = listEmployees.stream(); System.out.println("串行流findFirst: " + stream.findFirst().get()); try { System.out.println(stream.findAny().get()); } catch (IllegalStateException e) { e.printStackTrace(System.out); } System.out.println("串行流findAny: " + listEmployees.stream().findAny().get()); System.out.println("并行流findFirst: " + listEmployees.parallelStream().findFirst()); System.out.println("并行流findAny: " + listEmployees.parallelStream().findAny()); System.out.println("并行流findAny: " + listEmployees.parallelStream().findAny());
执行结果:
规约和收集 规约操作(reduction operation )又被称作折叠操作(fold ),是通过某个连接动作将所有元素汇总成一个结果的过程。例如:
1、对流做聚合操作:对流中元素求和、求平均值、求最大值、最小值、求元素总个数。如果对数字操作,也可由统计摘要获取。
2、将流转换成集合:将所有元素转换成一个列表或集合。
Stream 类库有两个通用的规约操作 reduce() 和 collect() ,也有一些为简化书写而设计的专用规约操作,比如 sum()、max()、min()、count() 等。
最大最小值这类规约操作很好理解(至少方法语义上是这样),重点是有魔法的 reduce() 和 collect() 。
count 返回流中元素总数。不可 由统计摘要获取。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 List<Long> list1 = listEmployees.stream().mapToLong(e -> 1L ).collect(new Supplier <List<Long>>() { @Override public List<Long> get () { return new ArrayList <>(); } }, new ObjLongConsumer <List<Long>>() { @Override public void accept (List<Long> dataList, long value) { dataList.add(value); } }, (dataList1, dataList2) -> dataList1.addAll(dataList2)); System.out.println(list1); List<Long> list2 = listEmployees.stream().mapToLong(e -> 1L ).collect(ArrayList::new , (dataList, i) -> dataList.add(i), (dataList1, dataList2) -> dataList1.addAll(dataList2)); System.out.println(list2); long count1 = listEmployees.stream().count();System.out.println(count1); long count2 = listEmployees.stream().mapToLong(e -> 1L ).sum();System.out.println(count2);
max和min 根据提供的 Comparator 返回此流最大或最小元素的 Optional。可 由统计摘要获取。
1 2 3 4 5 6 7 Integer maxAge = listEmployees.stream().map(e -> e.getAge()).max(Integer::compare).get();Integer minAge = listEmployees.stream().map(e -> e.getAge()).min(Integer::compare).get();System.out.println(maxAge); System.out.println(minAge); Double maxAge2 = listEmployees.stream().mapToDouble(e -> e.getAge()).summaryStatistics().getMax();
reduce
方法
描述
reduce(T iden, BinaryOperator b)
可以将流中元素反复结合 起来,得到一个值。 返回 T
reduce(BinaryOperator b)
可以将流中元素反复结合 起来,得到一个值。 返回 Optional
在Stream接口中的定义如下所示。
1 2 3 T reduce (T identity, BinaryOperator<T> accumulator) ; Optional<T> reduce (BinaryOperator<T> accumulator) ; <U> U reduce (U identity, BiFunction<U, ? super T, U> accumulator, BinaryOperator<U> combiner) ;
示例:
1 2 3 4 5 6 List<Integer> list = Arrays.asList(1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 ); Integer result = list.stream().reduce(0 , (x, y) -> x - y);System.out.println(result); System.out.println("----------------------------------------" ); Optional<Double> op = listEmployees.stream().map(Employee::getSalary).reduce(Double::sum); System.out.println(op.get());
我们也可以搜索 listEmployees 列表中“张”出现的次数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public static void main (String[] args) { Optional<Integer> sum = listEmployees.stream() .map(Employee::getName) .flatMap(Test::filterCharacter) .map((ch) -> { if (ch.equals('六' )) { return 1 ; } else { return 0 ; } }).reduce(Integer::sum); System.out.println(sum.get()); } public static Stream<String> filterCharacter (String str) { List<String> list = new ArrayList <>(); list.add(str); return list.stream(); }
注意:上述例子使用了硬编码的方式来累加某个具体值,应用时需根据实际优化代码。
Collector和Collectors java.util.stream.Collector:接口中方法的实现,决定了如何对流执行收集操作(如收集到 List、 Set、 Map)。
java.util.stream.Collectors:该工具类内部实现了 Collector(收集器) ;提供了很多静态方法 (各种有用的归约操作,例如将元素累积到集合中,根据各种标准对元素进行汇总等),可以方便地创建常见收集器实例。
Collectors介绍 部分方法与示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 public class Test { protected static List<Employee> listEmployees = Arrays.asList( new Employee ("张三" , 18 , 9999.99 , Employee.Stauts.SLEEPING), new Employee ("李四" , 38 , 5555.55 , Employee.Stauts.WORKING), new Employee ("王五" , 60 , 6666.66 , Employee.Stauts.WORKING), new Employee ("赵六" , 8 , 7777.77 , Employee.Stauts.SLEEPING), new Employee ("田七" , 58 , 8888.88 , Employee.Stauts.VOCATION) ); public static void main (String[] args) { String pattern = "%-25s %s %s" ; List employees1 = listEmployees.stream().collect(Collectors.toList()); System.out.printf(pattern, "toList: " , employees1, "\n" ); Set employees2 = listEmployees.stream().collect(Collectors.toSet()); System.out.printf(pattern, "toSet: " , employees2, "\n" ); Collection employees3 = listEmployees.stream().collect(Collectors.toCollection(ArrayList::new )); System.out.printf(pattern, "toCollection: " , employees3, "\n" ); long count = listEmployees.stream().collect(Collectors.counting()); System.out.printf(pattern, "counting: " , count, "\n" ); double total1 = listEmployees.stream().collect(Collectors.summingDouble(Employee::getSalary)); System.out.printf(pattern, "summingDouble: " , total1, "\n" ); double total2 = listEmployees.stream().collect(Collectors.reducing(0.0 , Employee::getSalary, Double::sum)); System.out.printf(pattern, "reducing: " , total2, "\n" ); double avg = listEmployees.stream().collect(Collectors.averagingDouble(Employee::getSalary)); System.out.printf(pattern, "averagingDouble: " , avg, "\n" ); DoubleSummaryStatistics dss = listEmployees.stream().collect(Collectors.summarizingDouble(Employee::getSalary)); System.out.printf(pattern, "summarizingDouble: " , dss.getMax(), "\n" ); System.out.printf(pattern, "summarizingDouble: " , dss.getSum(), "\n" ); List<String> strings = Arrays.asList("abc" , "" , "bc" , "efg" , "abcd" , "" , "jkl" ); System.out.printf(pattern, "joining: " , strings.stream().collect(Collectors.joining()), "\n" ); System.out.printf(pattern, "joining: " , strings.stream().collect(Collectors.joining("," )), "\n" ); System.out.printf(pattern, "joining: " , strings.stream().filter(string -> !string.isEmpty()).collect(Collectors.joining("," , "[" , "]" )), "\n" ); Optional max = listEmployees.stream().collect(Collectors.maxBy(Comparator.comparingDouble(Employee::getSalary))); System.out.printf(pattern, "maxBy: " , max.get(), "\n" ); Optional min = listEmployees.stream().collect(Collectors.minBy(Comparator.comparingDouble(Employee::getSalary))); System.out.printf(pattern, "minBy: " , min.get(), "\n" ); int how = listEmployees.stream().collect(Collectors.collectingAndThen(Collectors.toList(), List::size)); System.out.printf(pattern, "collectingAndThen: " , how, "\n" ); Map<Employee.Stauts, List<Employee>> map1 = listEmployees.stream().collect(Collectors.groupingBy(Employee::getStauts)); Map<Employee.Stauts, Set<Employee>> map2 = listEmployees.stream().collect(Collectors.groupingBy(Employee::getStauts, Collectors.toSet())); TreeMap<Employee.Stauts, String> map3 = listEmployees.stream().collect(Collectors.groupingBy(Employee::getStauts, TreeMap::new , Collectors.mapping(Employee::getName, Collectors.joining("," )))); System.out.printf(pattern, "groupingBy: " , map1, "\n" ); System.out.printf(pattern, "groupingBy: " , map2, "\n" ); System.out.printf(pattern, "groupingBy: " , map3, "\n" ); ConcurrentMap<Employee.Stauts, String> concurrentMap = listEmployees.parallelStream().collect(Collectors.groupingByConcurrent(Employee::getStauts, ConcurrentHashMap::new , Collectors.mapping(Employee::getName, Collectors.joining("," )))); System.out.printf(pattern, "groupingByConcurrent: " , concurrentMap, "\n" ); Map<Boolean, List<Employee>> vd = listEmployees.stream().collect(Collectors.partitioningBy(t -> t.getAge() > 50 )); System.out.printf(pattern, "partitioningBy: " , vd, "\n" ); String nameStr1 = listEmployees.stream().collect(Collectors.mapping(Employee::getName, Collectors.joining("," , "[" , "]" ))); String nameStr2 = listEmployees.stream().map(Employee::getName).collect(Collectors.joining("," , "[" , "]" )); System.out.printf(pattern, "mapping和map: " , nameStr1, "\n" ); System.out.printf(pattern, "mapping和map: " , nameStr2, "\n" ); Map<String, Integer> nameAgeMap = listEmployees.stream().collect(Collectors.toMap(e -> e.getName(), e -> e.getAge())); System.out.printf(pattern, "toMap: " , nameAgeMap, "\n" ); Map<String, Employee> strObjMap1 = listEmployees.stream().collect(Collectors.toMap(e -> e.getAge() < 40 ? "young" : "old" , e -> e, (e1, e2) -> e2)); System.out.printf(pattern, "toMap: " , strObjMap1, "\n" ); TreeMap<String, Employee> strObjMap2 = listEmployees.stream().collect(Collectors.toMap(e -> e.getAge() < 40 ? "young" : "old" , e -> e, (e1, e2) -> e2, TreeMap::new )); System.out.printf(pattern, "toMap: " , strObjMap2, "\n" ); System.out.println("--------------- toConcurrentMap ---------------" ); ConcurrentMap<String, Integer> nameAgeConcurrentMap = listEmployees.parallelStream().collect(Collectors.toConcurrentMap(e -> { System.out.println(e.getName()); return e.getName(); }, e -> e.getAge(), (e1, e2) -> e2, ConcurrentHashMap::new )); System.out.printf(pattern, "toConcurrentMap: " , nameAgeConcurrentMap, "\n" ); System.out.println("--------------- toConcurrentMap ---------------" ); } } @Data @Builder @ToString @NoArgsConstructor @AllArgsConstructor class Employee implements Serializable { private static final long serialVersionUID = -9079722457749166858L ; private String name; private Integer age; private Double salary; private Stauts stauts; public enum Stauts { WORKING, SLEEPING, VOCATION } }
collect 在Stream接口中的定义如下所示。
1 2 3 4 5 6 7 <R, A> R collect (Collector<? super T, A, R> collector) ; <R> R collect (Supplier<R> supplier, BiConsumer<R, ? super T> accumulator, BiConsumer<R, R> combiner) ;
参数为 Collector 对象实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 public class Test { public static void main (String[] args) { List<String> dataList = new ArrayList <>(); dataList.add("john" ); dataList.add("kain" ); dataList.add("mike" ); dataList.add("milk" ); dataList.add("kav" ); List<String> resultList = dataList.parallelStream().collect(new Collector <String, List<String>, List<String>>() { @Override public Supplier<List<String>> supplier () { return () -> new ArrayList <>(); } @Override public BiConsumer<List<String>, String> accumulator () { return (list, data) -> list.add(data.substring(0 , 1 ).toUpperCase().concat(data.substring(1 ))); } @Override public BinaryOperator<List<String>> combiner () { return (list1, list2) -> { list1.addAll(list2); return list1; }; } @Override public Function<List<String>, List<String>> finisher () { System.out.println("--执行--finisher" ); return list -> list; } @Override public Set<Characteristics> characteristics () { Set<Characteristics> characteristicsSet = new HashSet <>(); characteristicsSet.add(Characteristics.CONCURRENT); characteristicsSet.add(Characteristics.UNORDERED); characteristicsSet.add(Characteristics.IDENTITY_FINISH); return characteristicsSet; } }); resultList.forEach(System.out::println); } }
参数为三个对象实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public class Test { public static void main (String[] args) { List<String> dataList = new ArrayList <>(); dataList.add("john" ); dataList.add("kain" ); dataList.add("mike" ); dataList.add("milk" ); dataList.add("kav" ); List<String> resultList2 = dataList.parallelStream().collect( ArrayList::new , (list, data) -> list.add(data.substring(0 , 1 ).toUpperCase().concat(data.substring(1 ))), (list1, list2) -> list1.addAll(list2)); resultList2.forEach(System.out::println); } }
parallelStream线程安全问题
其中上面的两个例子中都使用了 parallelStream,并且使用了 collect 方法
parallelStream 可以提高数据处理效率,具体是通过将流中的数据分隔成若干端后再并行处理最后将结果合并
如果不使用 collect 方法会发生什么情况,会不会出现线程安全问题?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public class Test { private static Lock lock = new ReentrantLock (); public static void main (String[] args) { List<Integer> list1 = new ArrayList <>(); List<Integer> list2 = new ArrayList <>(); List<Integer> list3 = new ArrayList <>(); IntStream.range(0 , 10000 ).forEach(list1::add); IntStream.range(0 , 10000 ).parallel().forEach(list2::add); IntStream.range(0 , 10000 ).parallel().forEach(i -> { lock.lock(); try { list3.add(i); } finally { lock.unlock(); } }); System.out.println(String.format("串行执行的大小:%s" , list1.size())); System.out.println(String.format("有线程安全的并行问题大小:%s" , list2.size())); System.out.println(String.format("并行加锁:%s" , list1.size())); } }
执行结果如下,可见在 parallelStream 中会出现线程安全问题,虽然通过锁可以避免线程安全问题,但是会降低程序处理效率,从而影响系统的吞吐率。
1 2 3 串行执行的大小:10000 有线程安全的并行问题大小:8370 并行加锁:10000
正确的解决的方法就是通过 collect 方法和 Collector 接口,具体如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 public class Test { public static void main (String[] args) { List<Integer> list1 = new ArrayList <>(); IntStream.range(0 , 10000 ).forEach(list1::add); List<Integer> dataList = IntStream.range(0 , 10000 ).parallel().collect(new Supplier <List<Integer>>() { @Override public List<Integer> get () { System.out.println("new Supplier" ); return new ArrayList <>(); } }, new ObjIntConsumer <List<Integer>>() { @Override public void accept (List<Integer> dataList, int value) { dataList.add(value); } }, new BiConsumer <List<Integer>, List<Integer>>() { @Override public void accept (List<Integer> dataList1, List<Integer> dataList2) { System.out.println("merge result" ); dataList1.addAll(dataList2); } }); List<Integer> dataList1 = IntStream.range(0 , 10000 ).collect(ArrayList::new , (list, i) -> list.add(i), (lista, listb) -> lista.addAll(listb)); List<Integer> dataList2 = IntStream.range(0 , 10000 ).parallel().collect(ArrayList::new , (list, i) -> list.add(i), (lista, listb) -> lista.addAll(listb)); System.out.println(String.format("串行执行的大小:%s" , list1.size())); System.out.println(String.format("线程安全的并行大小:%s" , dataList.size())); System.out.println(String.format("线程安全的并行大小:%s" , dataList1.size())); System.out.println(String.format("线程安全的并行大小:%s" , dataList2.size())); } }
练习 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 public class Java8Tester { public static void main (String args[]) { System.out.println("使用 Java 7: " ); List<String> strings = Arrays.asList("abc" , "" , "bc" , "efg" , "abcd" , "" , "jkl" ); System.out.println("列表: " + strings); long count = getCountEmptyStringUsingJava7(strings); System.out.println("空字符串数量为: " + count); count = strings.stream().filter(string -> string.isEmpty()).count(); System.out.println("空字符串数量为: " + count); count = getCountLength3UsingJava7(strings); System.out.println("字符串长度为 3 的数量为: " + count); count = strings.stream().filter(string -> string.length() == 3 ).count(); System.out.println("字符串长度为 3 的数量为: " + count); List<String> filtered = deleteEmptyStringsUsingJava7(strings); System.out.println("筛选后的列表: " + filtered); filtered = strings.stream().filter(string -> !string.isEmpty()).collect(Collectors.toList()); System.out.println("筛选后的列表: " + filtered); String mergedString = getMergedStringUsingJava7(strings, ", " ); System.out.println("合并字符串: " + mergedString); mergedString = strings.stream().filter(string -> !string.isEmpty()).collect(Collectors.joining(", " )); System.out.println("合并字符串: " + mergedString); List<Integer> numbers = Arrays.asList(3 , 2 , 2 , 3 , 7 , 3 , 5 ); System.out.println("列表: " + numbers); List<Integer> squaresList = getSquaresUsingJava7(numbers); System.out.println("Squares List: " + squaresList); squaresList = numbers.stream().map(i -> i * i).distinct().collect(Collectors.toList()); System.out.println("Squares List: " + squaresList); List<Integer> integers = Arrays.asList(1 , 2 , 13 , 4 , 15 , 6 , 17 , 8 , 19 ); System.out.println("列表: " + integers); System.out.println("列表中最大的数 : " + getMaxUsingJava7(integers)); System.out.println("列表中最小的数 : " + getMinUsingJava7(integers)); System.out.println("所有数之和 : " + getSumUsingJava7(integers)); System.out.println("平均数 : " + getAverageUsingJava7(integers)); IntSummaryStatistics stats = integers.stream().mapToInt((x) -> x).summaryStatistics(); System.out.println("列表中最大的数 : " + stats.getMax()); System.out.println("列表中最小的数 : " + stats.getMin()); System.out.println("所有数之和 : " + stats.getSum()); System.out.println("平均数 : " + stats.getAverage()); System.out.println("随机数: " ); Random random = new Random (); for (int i = 0 ; i < 10 ; i++) { System.out.println(random.nextInt()); } random.ints().limit(10 ).sorted().forEach(System.out::println); count = strings.parallelStream().filter(string -> string.isEmpty()).count(); System.out.println("空字符串的数量为: " + count); } private static int getCountEmptyStringUsingJava7 (List<String> strings) { int count = 0 ; for (String string : strings) { if (string.isEmpty()) { count++; } } return count; } private static int getCountLength3UsingJava7 (List<String> strings) { int count = 0 ; for (String string : strings) { if (string.length() == 3 ) { count++; } } return count; } private static List<String> deleteEmptyStringsUsingJava7 (List<String> strings) { List<String> filteredList = new ArrayList <String>(); for (String string : strings) { if (!string.isEmpty()) { filteredList.add(string); } } return filteredList; } private static String getMergedStringUsingJava7 (List<String> strings, String separator) { StringBuilder stringBuilder = new StringBuilder (); for (String string : strings) { if (!string.isEmpty()) { stringBuilder.append(string); stringBuilder.append(separator); } } String mergedString = stringBuilder.toString(); return mergedString.substring(0 , mergedString.length() - 2 ); } private static List<Integer> getSquaresUsingJava7 (List<Integer> numbers) { List<Integer> squaresList = new ArrayList <Integer>(); for (Integer number : numbers) { Integer square = new Integer (number.intValue() * number.intValue()); if (!squaresList.contains(square)) { squaresList.add(square); } } return squaresList; } private static int getMaxUsingJava7 (List<Integer> numbers) { int max = numbers.get(0 ); for (int i = 1 ; i < numbers.size(); i++) { Integer number = numbers.get(i); if (number.intValue() > max) { max = number.intValue(); } } return max; } private static int getMinUsingJava7 (List<Integer> numbers) { int min = numbers.get(0 ); for (int i = 1 ; i < numbers.size(); i++) { Integer number = numbers.get(i); if (number.intValue() < min) { min = number.intValue(); } } return min; } private static int getSumUsingJava7 (List numbers) { int sum = (int ) (numbers.get(0 )); for (int i = 1 ; i < numbers.size(); i++) { sum += (int ) numbers.get(i); } return sum; } private static int getAverageUsingJava7 (List<Integer> numbers) { return getSumUsingJava7(numbers) / numbers.size(); } }
Base64 Java8 Base64 - 菜鸟