XML
相关链接: https://zh.wikipedia.org/wiki/XML
我们有时使用数据库仅仅是查询数据而已,可能并没有用到数据库独有的一些特性,比如数据的关联,数据的一致性、隔离性、持续性等。
处理数据的另一途径就是使用文件。读取文件的速度要远远快于与数据库建立连接的速度。要从文件中获取某些内容(比如:只获取姓名、性别),显然要对文件做分析处理,解析出所需要的内容。这就要求文件应当具有某种特殊的形式结构,即文件应当按照一定的标准来组织数据,这就是XML文件。
XML是由万维网联盟(World Wide Web Consortium,W3C)定义的一种语言,是表示结构化数据的行业标准。XML不仅提供了直接在数据上工作的通用方法,而且将用户界面和结构化数据相分离。XML文件就是按照XML语言表写的文本文件。
专门处理XML文件的API有很多,这些API的核心就是提供“XML解析器”,XML解析器是XML和应用程序之间的一个软件组织,其目的是为应用程序从XML文件中解析出所需要的数据。现使用的XML解析器普遍都是Java语言编写的。
一、XML文件的基本结构
XML是eXtensible Markup Language缩写,称为可扩展标记语言,XML允许用户按照XML的规则自定义标记。XML文件是由标记构成的文本文件,与HTML不同的是,标记可自由定义,目的是使得XML文件能够很好地体现数据的结构和含义,便于解析和理解其中的数据。W3C推出XML的主要目的是使得Internet上的数据相互交流更方便,让文件的内容更加浅显易懂。
1 | <?xml version="1.0" encoding="UTF-8"?> |
1.XML声明
<?xml version="1.0" encoding="UTF-8"?> // 必须是XML文件的首行
2.根标记
XML文件有且仅有一个根标记。上面XML文件的根标记是 “<列车时刻表>…</列车时刻表>”,分别是开始标记和结束标记。
3.树型结构
XML文件的根标记可以有若干个子标记,称为根标记的子标记。根标记的子标记还可以有子标记,以此类推,这样一来标记之间就形成了“子孙”关系。也可以称一个标记的子标记为该标记的1级标记,孙标记为该标记的2级标记等。上述XML文件的根标记的两个子标记
一个标记的内容中可以包含文本或其他的标记,其中被包含的标记称为该标记的子标记。如果一个标记仅仅包含文本,该标记称作,叶标记。
XML文件的标记必须形成树型结构,即一个标记的子标记必须包含于该标记的开始标记和结束标记之间。简单说,标记之间不允许出现交叉。下面是错误的,因为标记没有形成树型结构:
1 | <?xml version="1.0" encoding="UTF-8"?> |
二、XML声明
一个规范的XML文件应当以XML作为文件的第一行,在其前面不能有空白、其他的处理指令或注释。XML声明以 <?xml> 标记开始、以 ?> 标记结束。一下是一个最基本的XML声明:
<?xml version="1.0" ?>
1.XML声明中的版本属性
一个简单的XML文件声明中可以只包含属性 version (目前该属性的值只可以取1.0)。
2.XML声明中的编码属性
encoding属性,该属性规定XML文件采用哪种字符集进行编码。如果在XML声明中没有指定encoding属性的值,默认是UTF-8。
<?xml version="1.0" encoding="UTF-8"?>
如果使用UTF-8编码,那么标记以及标记的内容就可以使用汉字、日文、英文等,并且只能选择UTF-8编码来保存文件,XML解析器就能识别这些标记并正确解析标记中的内容。
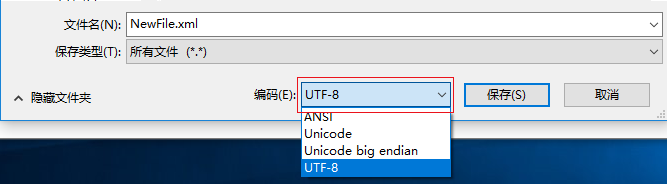
如果在编写XML文件时只准备使用ASCII字符和汉字,也可以将encoding属性的值设置为gb2312,但必须使用ANSI编码保存。
<?xml version="1.0" encoding="gb2312"?>
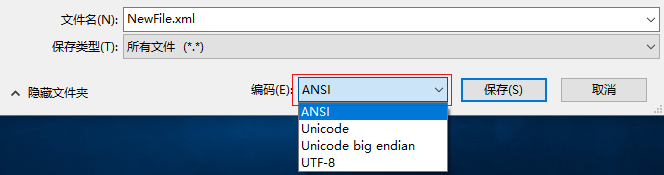
如果只准备使用ANSII字符,也可以将encoding属性的值设置为ISO-8859-1,文件必须使用ANSI编码保存。
三、标记
XML文件是由标记构成的文本文件标记的名称可以由字母、数字、下划线“_”、点号“.”、或连字符“-”组成,但必须以字母或下划线开头。
若使用UTF-8编码,字母也包括汉字、日文等。
标记名称区分大小写。
W3C对标记的使用有着严格的语法规定。
1.空标记
不含有子标记或文本内容的标记。不需要开始和结束标记。语法格式:
<空标记的名称 属性列表 />
或
<空标记的名称 />
例如:<chair width="24" height="12" /> 注意,在标记 “<” 和标记名称之间不要含有空格。
2.非空标记
含有子标记或文本内容的标记。有开始和结束标记。
<sex> 男 </sex> 正确
<birthday> 1980 年 8 月 15 日 </ birthday> 错误,”</“ 和birthday之间有空格
以下两个标记所含有的文本内容是不同的,因为第二个标记的内容中含有若干个空格和两个换行符。
<名称>电视</名称>
<名称>
电视
</名称>
3.CDATA段
XML有5种字符属于特殊字符,它们是左尖括号“<”、右尖括号“>”、与符号“&”、单引号“’”、双引号“””,XML有特殊用途,比如标记使用左、右尖括号等。标记内容中的文本数据不可以含有任何特殊符号。若想使用这些特殊符号,办法之一使用CDATA(Character Data)段。
CDATA段用 “” 作为段的结束,其中不可以有空格字符,开始和结束标记之间的内容可以包含任意字符。但是W3C规定,CDATA段不可以嵌套使用。例如:
1 | <hello> |
4.属性
为标记添加附加信息(不体现数据的结构)。属性是一个名值对,即属性必须由名字和值组成。属性必须在非空标记的开始标记或空标记中声明,用“=”为属性指定一个用单引号或双引号括起来的字符串(值)。
一个信息是否作为一个标记的属性或子标记,取决于具体问题。基本原则是:不要因属性的频繁使用而破坏XML的数据结构。下面是一个结构清晰的XML文件。
1 | <?xml version="1.0" encoding="UTF-8"?> |
如果把子标记中的数据改为父标记的属性值,XML文件的结构就显得很凌乱,如下:
1 | <root> |
四、DOM解析器
使用XML解析器可以从XML文件中解析出所需要的数据。有两种类型的解析器:基于DOM的解析器(DOM解析器)和基于事件的解析器(SAX解析器)。
文档对象模型(document object model,DOM)是W3C制定的一套规范标准。DOM规范的核心是按树型结构处理数据。
DOM解析器读入XML文件,按照DOM规范在内存中建立一个树型结构数据,XML文件的标记、标记含有的文本内容都会和内存中“树”的某个节点相对应。应用程序处理XML文档的方式是:操作内存中“树”的节点,获取所需要的数据。
下面介绍sun公司的DOM解析器,Sun公司发布的SDK1.5中提供了解析XML文件的API(Java API for XML parsing,JAXP)。
1.使用DOM解析器的步骤
在JAXP中,DOM解析器是DocumentBuilder类的一个实例,该实例由DocumentBuilderFactory类负责创建,步骤如下:
1 | import java.io.File; |
2.Document对象
DOM解析器负责在内存中建立Document对象。调用parse方法把解析的XML文件封装成一个Document对象,将XML文件和内存中的Document对象相对应。
结构
Document对象就是一颗“树”,是由实现了Node接口的Element类、Text类和CDATASection类的实例组成的树型结构数据,这些实例分别称为Document对象中的Element节点、Text节点和CDATASection节点,文件中的标记都和Document对象中的某个节点相对应。
一个Element节点中还可以有Element节点、Text节点、CDATASection节点。比如Document对象的根节点就是Element类的一个实例,即是一个Element节点。
下面是 XML 文件和相对应的 Document 对象:
1 | <?xml version="1.0" encoding="UTF-8"?> |
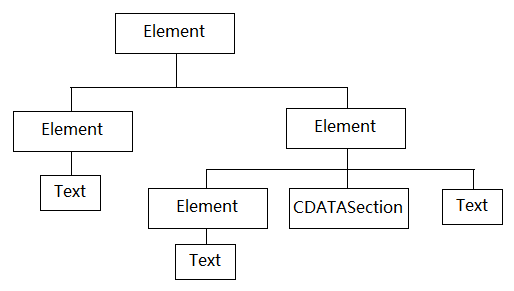
重要节点
A.Element节点。获取和该节点相关的信息的常用方法:
String getTagName():返回该节点的名称,该名称就是和此节点相对应的XML中的标记的名称。
String getTextContent():返回当前节点的所有Text子孙节点中的文本内容(也就是返回相应的XML文件中的标记及其子孙标记中含有的文本内容)。
String getAttribute(String name):返回该节点中参数name指定的属性的值,该属性值是和此节点对应的XML中的标记中属性的值。
NodeList getChildNodes():返回一个NodeList对象,该对象由当前节点的子节点组成。
NodeList getElementsByTagName(String name):返回一个NodeList对象,该对象由当前节点的Element类型子孙节点组成,这些子孙节点的名字由参数name指定。
boolean hasAttribute(String name):判断当前节点是否有 名字由参数name指定的属性。
B.Text节点。使用 String getWholeText() 方法获取该节点中的文本(包括其中的空白字符)。
C.CDATASection节点。使用 String getWholeText() 方法获取该节点中的文本,即CDATA段中的文本(包括其中的空白字符)。
3.查询成绩
例子:使用DOM解析器从XML文件中解析出所需要的数据