推荐链接
https://www.oraclejsq.com/article/010101878.html
https://www.cnblogs.com/linjiqin/archive/2012/04/04/2431975.html
语法结构 1 2 3 select table.column, Analysis_function() OVER ([partition by 字段] [order by 字段 [windows]]) as 统计值 from table
语法解析:
1、Analysis_function:指定分析函数名,常用的分析函数有sum、max、first_value、last_value、rank、row_number等等。
2、over():开窗函数
partition by: 指定进行数据分组的字段 。
order by: 指定进行排序的字段 。
windows: 排序时 指定的数据窗口(即指定分析函数要操作的行数 )。排序不指定窗口时,以组内当前行之前所有数据做为窗口 。
若没有 order by 也就不需要 windows。
使用的语法形式大概如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 over (partition by xxx order by yyy rows between zzz)
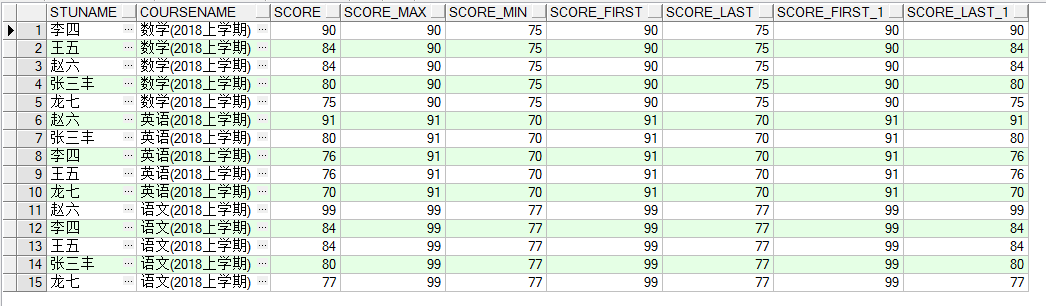
max、min、first_value、last_value max:返回组中的最大值。
min:返回组中的最小值。
first_value:返回组中数据窗口的第一个值
last_value:返回组中数据窗口的最后一个值。通过对某个字段排序,可以在一定窗口内获取最大值和最小值。
案例:利用min、max分别取出不同课程当中的学生成绩的最高值和最低值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 select c.stuname, b.coursename, t.score, max (t.score) over (partition by t.courseid) as score_max, min (t.score) over (partition by t.courseid) as score_min, first_value (t.score) over (partition by t.courseid order by t.score desc ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) as score_first, last_value (t.score) over (partition by t.courseid order by t.score desc ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) as score_last, first_value (t.score) over (partition by t.courseid order by t.score desc ) as score_first_1, last_value (t.score) over (partition by t.courseid order by t.score desc ) as score_last_1 from STUDENT.SCORE t, student.course b, student.stuinfo c where t.courseid = b.courseid and t.stuid = c.stuid
row_number、rank row_number/rank:根据开窗函数中排序的字段返回在组内的有序的偏移量,即可得到在组内的位置。
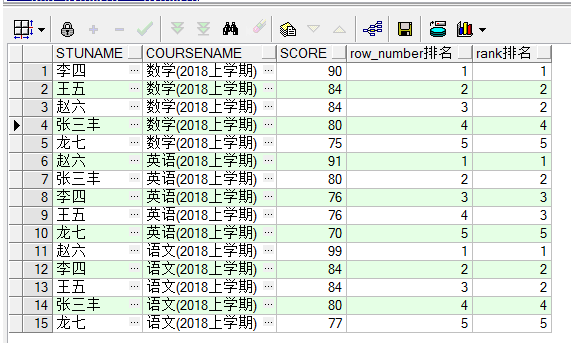
案例:利用row_number、rank获取学生课程成绩的排名
1 2 3 4 5 6 7 8 9 10 11 select c.stuname, b.coursename, t.score, row_number () over (partition by t.courseid order by t.score desc ) as "row_number排名", rank () over (partition by t.courseid order by t.score desc ) as "rank排名" from STUDENT.SCORE t, student.course b, student.stuinfo c where t.courseid = b.courseid and t.stuid = c.stuid
ROW_NUMBER函数排名是返回一个唯一的值,当碰到相同数据时,排名按照记录集中记录的顺序依次递增。
rank函数返回一个唯一的值,但是当碰到相同的数据时,此时所有相同数据的排名是一样的,同时会在最后一条相同记录和下一条不同记录的排名之间空出排名。比如数学成绩都是84分的两个人并列第二名,但是“张三丰”同学就是直接是第四名。
我们经常会利用row_number函数的排名机制(排名的唯一性)来过滤重复数据 ,即按照某一个特定的排序条件,通过获取排名为1的数据来获取重复数据当中最新的数据值。