字符编码
推荐链接:
字符编码笔记:ASCII,Unicode 和 UTF-8 - 阮一峰
历史 (Unicode诞生)
计算机起源于美国,上个世纪,他们对英语字符与二进制位之间的关系做了统一规定,并制定了一套字符编码规则,这套编码规则被称为 ASCII 编码。
ASCII 编码一共定义了128个字符的编码规则,用七位二进制表示 ( 0x00 - 0x7F ),这些字符组成的集合就叫做 ASCII 字符集。
随着计算机的普及,在不同的地区和国家又出现了很多字符编码,比如: 大陆的 GB2312、港台的 BIG5,日本的 Shift JIS等等。
由于字符编码不同,计算机在不同国家之间的交流变得很困难,经常会出现乱码的问题,比如:对于同一个二进制数据,不同的编码会解析出不同的字符。
当互联网迅猛发展,地域限制打破之后,人们迫切的希望有一种统一的规则,对所有国家和地区的字符进行编码,于是 Unicode 就出现了。
ASCII
ASCII 码是大多数常用编码的基础(也许存在不以 ASCII 为基础的编码方式吧),它是一个7位的编码标准,包括26个小写字母、26个大写字母、10个数字、32个符号、33个控制代码和一个空格,共128个代码。
ASCII 码的扩充:ANSI、UNICODE、GB2312 等字符集。
ANSI
ANSI 是一种字符代码,并不是字符编码,在不同区域设置的系统中,ANSI表示不同的编码。
在简体中文Windows操作系统中,ANSI 编码代表 GB2312编码;在繁体中文Windows操作系统中,ANSI编码代表Big5;在日文Windows操作系统中,ANSI 编码代表 JIS 编码。
乱码
在中文系统中创建一个文本文件,使用默认的 ANSI 编码,输入一段中文
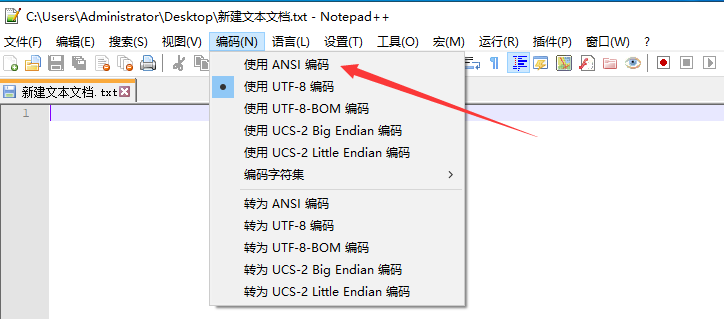
在英文系统中(或修改区域设置)打开这个文本文件,这时就会乱码,因为操作系统区域设置不同,编码方式不同。
Windows查看ANSI
微软用一个叫 Code page 表示系统默认编码。
对于Windows操作系统中的命令行窗口(Command Prompt),chcp命令在没有参数时,显示当前代码页;chcp命令带一个整数参数,则改变命令行窗口的当前代码页为参数所指定。
Windows 下 Code page 由系统的 区域设置(locale) - 维基百科 决定,win10修改区域设置:
Linux查看ANSI
1 | locale # 查看locale |
字符集+字符编码
字符集是很多个字符的集合。比如:GB2312、GBK 是 字符集 又是 字符编码,UNICODE 只是字符集。
字符编码是字符集的一种实现方式,把字符集中的字符映射为特定的字节或字节序列,它是一种规则。比如:UTF-8、UTF-16、UTF-32 等 可变长字符编码 规则。
GB2312
字符集 + 字符编码(自成体系)。
GBK
字符集 + 字符编码(自成体系),是对 GB2312 的扩展。
UNICODE
是字符集,不是编码方,但它确实定义了“编码方案框架”。
官方中文名称为统一码,又译作万国码、统一字符码、统一字符编码,是计算机科学领域的业界标准。它将世界各种语言的每个字符定义一个唯一的编码,以满足跨语言、跨平台的文本信息转换。
Unicode 字符集的码点范围是 0x0000 - 0x10FFFF,共可容纳超过一百万个字符。每个字符在 Unicode 中都有一个唯一的编码值,这个编码值就是一个二进制数,被称为 码点(Code Point)。例如,汉字 “中” 的码点是 0x4E2D,大写字母 A 的码点是 0x41。
码点可以在 Unicode 标准中查询,每个字符都有唯一的码点进行标识。一般来说,每个码点对应一个字符,每个字符也对应一个码点。但在某些情况下,比如 Emoji 字符、组合字符、变体字符或控制符,一个“字符”可能由多个码点组成,或者有些码点不对应可见字符。
可变长字符编码
Unicode 的码点范围是从 0x0000 到 0x10FFFF,最多只需要 21 位二进制就能表示所有字符。理论上,3 个字节(24 位)就足够容纳这些码点。
但如果所有字符都统一用 3 个字节存储,会浪费大量空间,尤其是对于码点较小的字符,比如 ASCII,只需 1 个字节即可表示。
这就带来一个问题:如果字符长度不固定,计算机如何知道每次读取几个字节?
为了解决这个问题,Unicode 设计了多种可变长度编码方案,根据字符的码点范围动态分配字节数,以兼顾空间效率和表示能力。常见的编码方式有:
- UTF-8:用 1 到 4 个字节表示字符,小码点用少字节,高码点用多字节,兼容 ASCII,且易于解码。
- UTF-16:用 2 或 4 个字节表示字符。
- UTF-32:每个字符固定使用 4 个字节,简单但占空间。
通过这种方式,既节省了空间,又能确保字符编码和解码的正确性。
| Unicode 码点范围 | UTF-8 字节数 | UTF-16 字节数 | UTF-32 字节数 |
|---|---|---|---|
| U+0000 ~ U+007F | 1 字节 | 2 字节 | 4 字节 |
| U+0080 ~ U+07FF | 2 字节 | 2 字节 | 4 字节 |
| U+0800 ~ U+FFFF | 3 字节 | 2 字节 | 4 字节 |
| U+10000 ~ U+10FFFF | 4 字节 | 4 字节(代理对) | 4 字节 |
UTF-8 编码
UTF-8: 是一种变长字符编码,被定义为将码点编码为 1 至 4 个字节,具体取决于码点数值中有效二进制位的数量。
UTF-8 的编码规则:
对于单字节的符号,字节的第一位设为 0,后面 7 位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的,所以 UTF-8 能兼容 ASCII 编码,这也是互联网普遍采用 UTF-8 的原因之一。
对于 n 字节的符号( n > 1),第一个字节的前 n 位都设为 1,第 n + 1 位设为 0,后面字节的前两位一律设为 10 。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
下表是Unicode编码对应UTF-8需要的字节数量以及编码格式:
| Unicode编码范围(16进制) | UTF-8编码方式(二进制) |
|---|---|
| 000000 - 00007F | 0xxxxxxx ASCII码 |
| 000080 - 0007FF | 110xxxxx 10xxxxxx |
| 000800 - 00FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 01 0000 - 10 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
表格中第一列是Unicode编码的范围,第二列是对应UTF-8编码方式,其中红色的二进制 “1” 和 “0” 是固定的前缀,字母 x 表示可用编码的二进制位。
根据上面表格,要解析 UTF-8 编码就很简单了,如果一个字节第一位是 0 ,则这个字节就是一个单独的字符,如果第一位是 1 ,则连续有多少个 1 ,就表示当前字符占用多少个字节。
下面以 “中” 字 为例来说明 UTF-8 的编码,具体的步骤如下图, 为了便于说明,图中左边加了 1,2,3,4 的步骤编号。
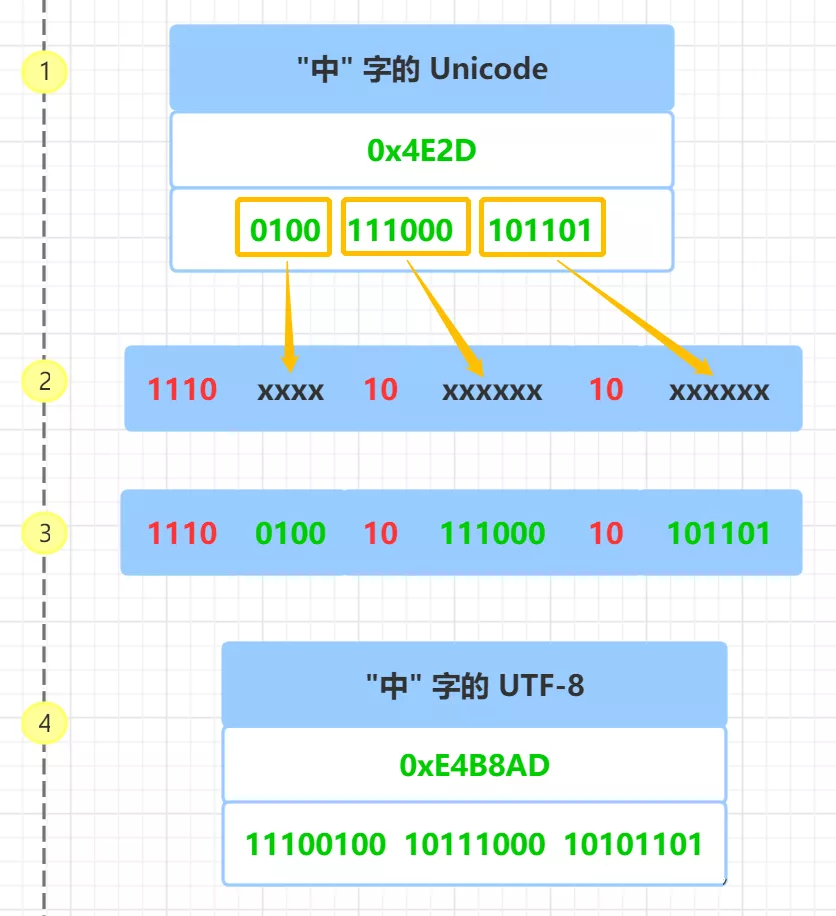
首先查询 “中” 字的 Unicode 码 0x4E2D,转成二进制,总共有 16 个二进制位, 具体如上图 步骤1 所示。
通过前面的 Unicode 编码和 UTF-8 编码的表格知道,Unicode 码 0x4E2D 对应 000800 - 00FFFF 的范围,所以,“中” 字的 UTF-8 编码 需要 3 个字节,即格式是 1110xxxx 10xxxxxx 10xxxxxx 。
然后从 “中” 字的最后一个二进制位开始,按照从后向前的顺序依次填入格式中的 x 字符,多出的二进制补为 0, 具体如上图 步骤2、步骤3 所示。
于是,就得到了 “中” 的 UTF-8 编码是 11100100 10111000 10101101,转换成十六进制就是 0xE4B8AD, 具体如上图 步骤4 所示。
UTF-16 编码
UTF-16 也是一种变长字符编码,这种编码方式比较特殊,它将字符编码成 2 字节 或者 4 字节。
具体的编码规则如下:
对于 Unicode 码小于 0x10000 的字符, 使用 2 个字节存储,并且是直接存储 Unicode 码,不用进行编码转换。
对于 Unicode 码在 0x10000 和 0x10FFFF 之间的字符,使用 4 个字节存储,这 4 个字节分成前后两部分,每个部分各两个字节,其中,前面两个字节的前 6 位二进制固定为 110110,后面两个字节的前 6 位二进制固定为 110111,前后部分各剩余 10 位二进制表示符号的 Unicode 码减去 0x10000 的结果。
大于 0x10FFFF 的 Unicode 码无法用 UTF-16 编码。
下表是Unicode编码对应UTF-16编码格式:
| Unicode编码范围(16进制) | 具体Unicode码(二进制) | UTF-16编码方式(二进制) | 字节 |
|---|---|---|---|
| 0000 0000 - 0000 FFFF | xxxxxxxx xxxxxxxx | xxxxxxxx xxxxxxxx | 2 |
| 0001 0000 - 0010 FFFF | yy yyyyyyyy xx xxxxxxxx | 110110yy yyyyyyyy 110111xx xxxxxxxx | 4 |
表格中第一列是Unicode编码的范围,第二列是具体Unicode码的二进制 ( 第二行的第二列表示的是 Unicode 码减去 0x10000 后的二进制 ) ,第三列是对应UTF-16编码方式,其中红色的二进制 “1” 和 “0” 是固定的前缀,字母 x 和 y 表示可用编码的二进制位, 第四列表示 编码占用的字节数。
前面提到过,“中” 字的 Unicode 码是 4E2D,它小于 0x10000,根据表格可知,它的 UTF-16 编码占两个字节,并且和 Unicode 码相同,所以 “中” 字的 UTF-16 编码为 4E2D。
我从 Unicode字符表网站 找了一个老的南阿拉伯字母,它的 Unicode 码是: 0x10A6F ,可以访问 https://unicode-table.com/cn/10A6F/ 查看字符的说明,Unicode 码对应的字符如下图所示:

下面以这个 老南阿拉伯字母 的 Unicode 码 0x10A6F 为例来说明 UTF-16 4 字节的编码,具体步骤如下,为了便于说明,图中左边加了 1,2,3,4 、5的步骤编号:
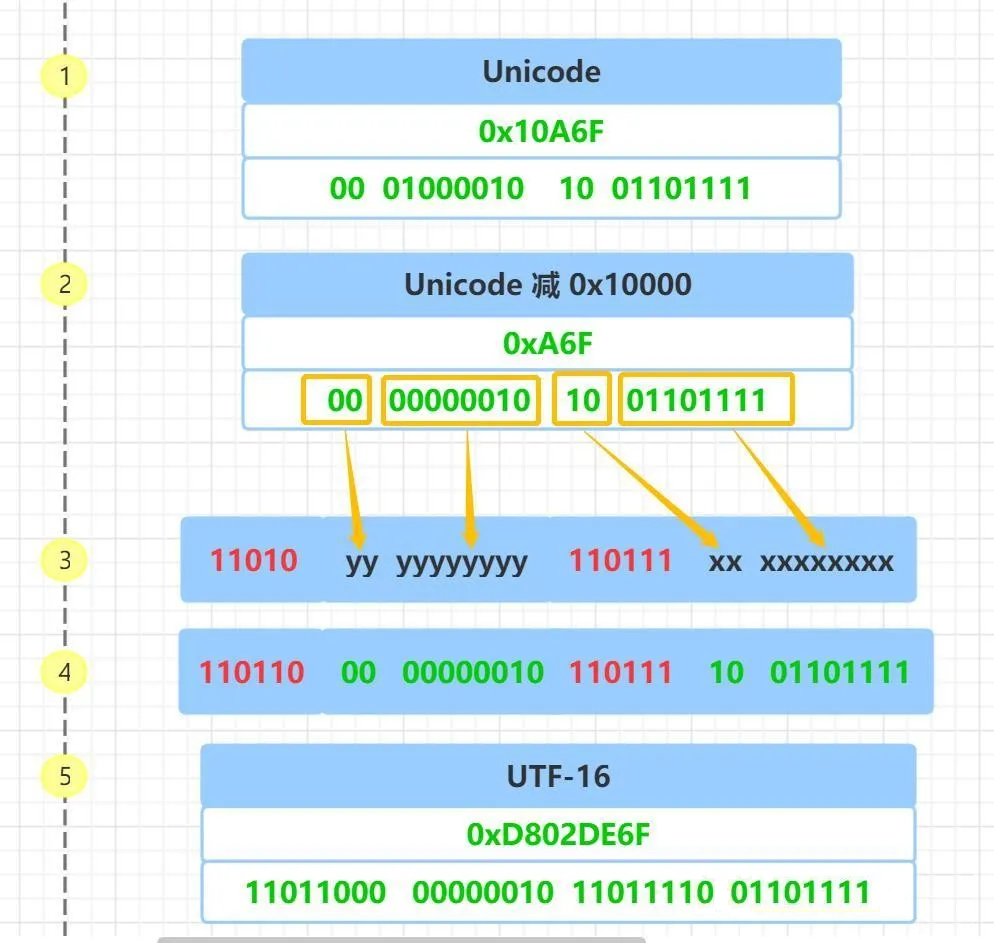
首先把 Unicode 码 0x10A6F 转成二进制,对应上图的 步骤 1。
然后把 Unicode 码 0x10A6F 减去 0x10000,结果为 0xA6F 并把这个值转成二进制 00 00000010 10 01101111,对应上图的 步骤 2。
然后 从二进制 00 00000010 10 01101111 的最后一个二进制为开始,按照从后向前的顺序依次填入格式中的 x 和 y 字符,多出的二进制补为 0, 对应上图的 步骤 3、 步骤 4。
于是,就计算出了 Unicode 码 0x10A6F 的 UTF-16 编码是 11011000 00000010 11011110 01101111 ,转换成十六进制就是 0xD802DE6F, 对应上图的 步骤 5。
UTF-32 编码
UTF-32 是固定长度的编码,始终占用 4 个字节,足以容纳所有的 Unicode 字符,所以直接存储 Unicode 码即可,不需要任何编码转换。虽然浪费了空间,但提高了效率。
UTF-8、UTF-16、UTF-32 之间如何转换
前面介绍过,UTF-8、UTF-16、UTF-32 是 Unicode 码表示成不同的二进制格式的编码规则,同样,通过这三种编码的二进制表示,也能获得对应的 Unicode 码,有了字符的 Unicode 码,按照上面介绍的 UTF-8、UTF-16、UTF-32 的编码方法,就能转换成任一种编码了。
UTF 字节顺序
最小编码单元是多字节才会有字节序的问题存在,UTF-8 最小编码单元是一字节,所以它是没有字节序的问题,UTF-16 最小编码单元是 2 个字节,在解析一个 UTF-16 字符之前,需要知道每个编码单元的字节序。
比如:前面提到过,“中” 字的 Unicode 码是 4E2D,“ⵎ” 字符的 Unicode 码是 2D4E, 当我们收到一个 UTF-16 字节流 4E2D 时,计算机如何识别它表示的是字符 “中” 还是 字符 “ⵎ” 呢 ?
所以,对于多字节的编码单元,需要有一个标记显式的告诉计算机,按照什么样的顺序解析字符,也就是字节序,字节序分为 大端字节序 和 小端字节序。
小端字节序简写为 LE( Little-Endian ),表示 低位字节在前,高位字节在后,高位字节保存在内存的高地址端,而低位字节保存在内存的低地址端。
大端字节序简写为 BE( Big-Endian ),表示 高位字节在前,低位字节在后,高位字节保存在内存的低地址端,低位字节保存在在内存的高地址端。
下面以 0x4E2D 为例来说明大端和小端,具体参见下图:
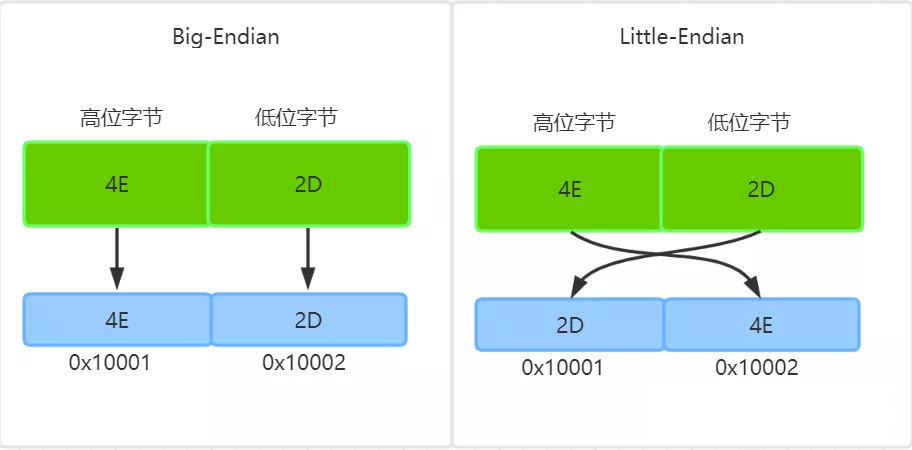
数据是从高位字节到低位字节显示的,这也更符合人们阅读数据的习惯,而内存地址是从低地址向高地址增加。
所以,字符 0x4E2D 数据的高位字节是 4E,低位字节是 2D。
按照大端字节序的高位字节保存内存低地址端的规则,4E 保存到低内存地址 0x10001 上,2D 则保存到高内存地址 0x10002 上。
对于小端字节序,则正好相反,数据的高位字节保存到内存的高地址端,低位字节保存到内存低地址端的,所以 4E 保存到高内存地址 0x10002 上,2D 则保存到低内存地址 0x10001 上。
BOM (字节顺序标记)
BOM 是 byte-order mark 的缩写,是 “字节顺序标记” 的意思,它常被用来当做标识文件是以 UTF-8、UTF-16 或 UTF-32 编码的标记。
在 Unicode 编码中有一个叫做 “零宽度非换行空格” 的字符 ( ZERO WIDTH NO-BREAK SPACE ),用字符 FEFF 来表示。
对于 UTF-16 ,如果接收到以 FEFF 开头的字节流, 就表明是大端字节序,如果接收到 FFFE, 就表明字节流 是小端字节序。
UTF-8 没有字节序问题,上述字符只是用来标识它是 UTF-8 文件,而不是用来说明字节顺序的。“零宽度非换行空格” 字符 的 UTF-8 编码是 EF BB BF,所以如果接收到以 EF BB BF 开头的字节流,就知道这是UTF-8 文件。
下面的表格列出了不同 UTF 格式的固定文件头:
| UTF编码 | 固定文件头 |
|---|---|
| UTF-8 | EF BB BF |
| UTF-16LE | FF FE |
| UTF-16BE | FE FF |
| UTF-32LE | FF FE 00 00 |
| UTF-32BE | 00 00 FE FF |
根据上面的 固定文件头,下面列出了 “中” 字在文件中的存储 ( 包含文件头 ):
| 编码 | 固定文件头 |
|---|---|
| Unicode 编码 | 0X004E2D |
| UTF-8 | EF BB BF 4E 2D |
| UTF-16BE | FE FF 4E 2D |
| UTF-16LE | FF FE 2D 4E |
| UTF-32BE | 00 00 FE FF 00 00 4E 2D |
| UTF-32LE | FF FE 00 00 2D 4E 00 00 |
常见的字符编码的问题
Redis 中文key的显示
有时候我们需要向redis中写入含有中文的数据,然后在查看数据,但是会看到一些其他的字符,而不是我们写入的中文
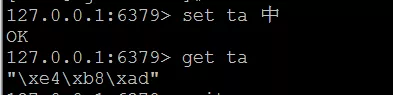
上图中,我们向redis 写入了一个 “中” 字,通过 get 命令查看的时候无法显示我们写入的 “中” 字。
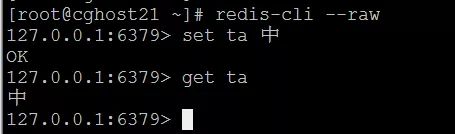
这时候加一个 –raw 参数,重新启动 redis-cli 即可,也即 执行 redis-cli –raw 命令启动redis客户端,具体的如下图所示
MySQL 中的 utf8 和 utf8mb4
MySQL 中的 “utf8” 实际上不是真正的 UTF-8,它只支持每个字符最多 3 个字节,对于超过 3 个字节的字符就会出错。而真正的 UTF-8 支持 4 个字节。
MySQL 中的 “utf8mb4” 才是真正的 UTF-8。
下面以 test 表为例来说明,表结构如下:
1 | mysql> show create table test\G |
向 test 表分别插入 “中” 字 和 Unicode 码为 0x10A6F 的字符,这个字符需要从 https://unicode-table.com/cn/10A6F/ 直接复制到 MySQL 控制台上,手工输入会无效,具体的执行结果如下图:

从上图可以看出,插入 “中” 字 成功,插入 0x10A6F 字符失败,错误提示无效的字符串,\xF0\X90\XA9\xAF 正是 0x10A6F 字符的 UTF-8 编码,占用 4 个字节,因为 MySQL 的 utf8 编码最多只支持 3 个字节,所以插入会失败。
把 test 表的字符集改成 utf8mb4 ,排序规则 改成 utf8bm4_unicode_ci,具体如下图所示:
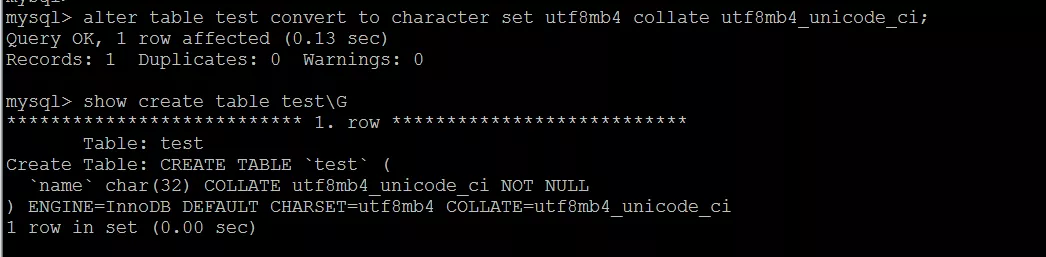
字符集和排序方式修改之后,再次插入 0x10A6F 字符, 结果是成功的,具体执行结果如下图所示:
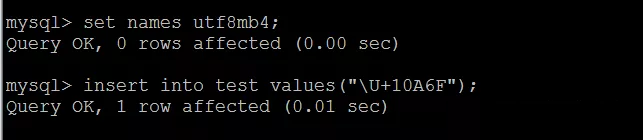
上图中,set names utf8mb4 是为了测试方便,临时修改当前会话的字符集,以便保持和服务器一致,实际解决这个问题需要修改 my.cnf 配置中 服务器和客户端的字符集。