大数据技术栈
Hadoop
https://zh.wikipedia.org/zh-cn/Apache_Hadoop
https://hadoop.apache.org/
Apache Hadoop 是一个开源软件框架,它使用简单的编程模型提供高度可靠的大型数据集分布式处理。Hadoop 以其可扩展性而闻名,它构建在商用计算机集群上,为存储和处理大量结构化、半结构化和非结构化数据提供了经济高效的解决方案,且没有格式要求。
Apache Hadoop的核心模块分为存储和计算模块。Apache Hadoop框架由以下基本模块构成:
Hadoop Common – 包含了其他 Hadoop 模块所需的库和实用程序;在0.20及以前的版本中,包含HDFS、MapReduce和其他项目公共内容,从0.21开始HDFS和MapReduce被分离为独立的子项目,其余内容为Hadoop Common
Hadoop Distributed File System (HDFS,Hadoop分布式文件系统) – 一种将数据存储在集群中多个节点中的分布式文件系统,能够提供很高的带宽;
Hadoop MapReduce – 用于大规模数据处理的MapReduce计算模型实现;
Hadoop YARN – (于2012年引入) 一个负责管理集群中计算资源,并实现用户程序调度的平台;
Hadoop Ozone – (于2020年引入) Hadoop的对象存储。
Apache Hadoop的MapReduce和HDFS模块的灵感来源于Google的 MapReduce 和 Google File System 论文。
大致工作流程:Hadoop框架先将文件分成数据块并分布式地存储在集群的计算节点中,接着将负责计算任务的代码传送给各节点,让其能够并行地处理数据。这种方法有效利用了数据局部性,令各节点分别处理其能够访问的数据。与传统的超级计算机架构相比,这使得数据集的处理速度更快、效率更高。
HDFS
https://www.ibm.com/cn-zh/topics/hdfs
[HDFS概述介绍及其优缺点](https://blog.csdn.net/mr123666/article/details/103310926)
HDFS 是一种分布式文件系统,用于处理在商业硬件上运行的大型数据集。 它用于将单个 Apache Hadoop 集群扩展到数百 (甚至数千)个节点。 HDFS 不应与 Apache HBase 混淆或被 Apache HBase 取代,Apache HBase 是一个面向列的非关系数据库管理系统,它位于 HDFS 之上,可以通过其内存处理引擎更好地支持实时数据需求。
MapReduce
https://www.ibm.com/cn-zh/topics/mapreduce
MapReduce 是一种编程范式,它允许在 Hadoop 聚类中的数百或数千台服务器之间进行大规模扩展。 作为处理组件,MapReduce 是 Apache Hadoop 的核心。 术语“MapReduce”指的是 Hadoop 程序执行的两个不同的独立任务。 第一个是映射作业,它接受一组数据,并将其转换为另一组数据,其中各个元素分解为元组(键/值对)。
缩减作业以映射的输出作为输入,并将这些数据元组组合为更小的一组元组。 正如名称 MapReduce 的顺序所暗示的那样,缩减作业总是在映射作业之后执行。
MapReduce 编程提供了一些优势,有助于从您的大数据获得宝贵的洞察:
- 可扩展性。 企业可以处理 Hadoop Distributed File System (HDFS) 中存储的 PB 级数据。
- 灵活性。 利用 Hadoop,可以更轻松地访问多个数据源和多个类型的数据。
- 速度。 利用并行处理和最小数据迁移,Hadoop 提供了大量数据的快速处理。
- 简便易用。 开发者可以使用一系列语言(包括 Java、C++ 和 Python)编写代码。
HBase
https://zh.wikipedia.org/zh-cn/Apache_HBase
https://HBase.apache.org/
https://www.ibm.com/cn-zh/topics/HBase
Hadoop database 的简称。是一款基于 Hadoop HDFS 的数据库,是一种NoSQL数据库,主要适用于海量明细数据(十亿、百亿)的随机实时查询,如日志明细、交易清单、轨迹行为等。
HBase 是一个在 HDFS 上运行的列式存储非关系数据库管理系统。 HBase 提供了存储稀疏数据集的容错方式,这类数据集在许多大数据用例中十分常见。 它非常适合实时数据处理或者对大量数据的随机读取/写入访问。
与关系数据库系统不同,HBase 不支持 SQL 一类的结构化查询语言;事实上,HBase 根本不是关系数据存储库。 HBase 应用程序以 Java 编写,更像是一款典型的 Apache MapReduce 应用程序。 HBase 确实支持以 Apache Avro、REST 和 Thrift 编写应用程序。
HBase 系统设计为线性扩展。 它包括一系列由行和列组成的标准表,更像是传统数据库。 每个表必须有一个定义为主键的元素,且所有对 HBase 表的访问尝试都必须使用此主键。
Avro 作为组件,支持一系列丰富的原始数据类型(包括数字、二进制数据和字符串)以及多种复杂类型(包括数组、映射、枚举和记录)。 对于数据,也可以定义排序顺序。
HBase 依赖于 zookeeper 实现高性能协调。 zookeeper 内置到 HBase 中,但如果您正在运行生产集群,那么建议您配备一个与 HBase 集成的专用 ZooKeeper 集群。
HBase 非常适合与 Hive 结合使用,后者是用于大数据批处理的查询引擎,以支持容错性大数据应用程序。
维基百科
HBase是一个开源的<font color="red">非关系型分布式数据库(NoSQL)</font>,它参考了谷歌的BigTable建模,实现的编程语言为 Java。它是Apache软件基金会的Hadoop项目的一部分,运行于HDFS文件系统之上,为 Hadoop 提供类似于BigTable 规模的服务。因此,它可以对稀疏文件提供极高的容错率。 HBase在列上实现了BigTable论文提到的压缩算法、内存操作和布隆过滤器。HBase的表能够作为MapReduce任务的输入和输出,可以通过Java API来访问数据,也可以通过REST、Avro或者Thrift的API来访问。 虽然最近性能有了显著的提升,HBase 还不能直接取代SQL数据库。如今,它已经应用于多个数据驱动型网站,包括 Facebook的消息平台。 在 Eric Brewer的 [CAP理论](https://zh.wikipedia.org/zh-cn/CAP%E5%AE%9A%E7%90%86) 中,HBase属于CP类型的系统。
总结:
- HBase中的表是物理表,不是逻辑表,提供一个超大的内存hash表,搜索引擎通过它来存储索引,方便查询操作。
- HBase可以认为是 HDFS 的一个包装。它的本质是数据存储,是个NoSql数据库。它基于列的而不是基于行的模式处理数据,相比 HDFS 更适合海量数据的随机访问。
- HBase的表是疏松型,因此用户可以给行定义各种不同的列。
- HBase是近实时系统,支持实时查询。
- HBase支持row-level的更新。
- HBase不使用与有join、多级索引、表关系复杂的应用场景。
Hive
https://zh.wikipedia.org/zh-cn/Apache_Hive
https://hive.apache.org/
Hive 是基于Hadoop的一个<font color="red">数据仓库工具</font>,<font color="red">可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,并将SQL语句最终转换为 **MapReduce** 任务进行运行。</font>主要是让开发人员能够通过 SQL 来计算和处理 HDFS 上的结构化数据,**适用于离线的批量数据计算**。
Apache Hive 是一种分布式、容错的数据仓库系统,可实现大规模分析。<font color="red">Hive Metastore (HMS) 提供了一个元数据的中央存储库,</font>可以轻松分析该元数据以做出明智的、数据驱动的决策,因此它是许多数据湖架构的关键组件。Hive 构建在 Apache Hadoop 之上,通过 hdfs 支持 S3、adls、gs 等存储。Hive 允许用户使用 SQL 读取、写入和管理分布式存储中的 PB 级数据。
通过元数据来描述 HDFS 上的结构化文本数据,通俗点来说,就是定义一张表来描述HDFS上的结构化文本,包括各列数据名称,数据类型是什么等,方便我们处理数据,当前很多SQL ON Hadoop的计算引擎均用的是hive的元数据,如Spark SQL、Impala等;
总结:
- Hive中的表是纯逻辑表,就只是表的定义等,即表的元数据。Hive 本身不存储和计算数据,它完全依赖于HDFS存储文件和MapReduce计算框架。
- Hive可以认为是 MapReduce 的一个包装,它基于 MapReduce 处理数据,而 MapReduce 基于行的模式处理数据。Hive 的意义就是把好写的 HiveSQL 转换为复杂难写的 map-reduce 程序。
- Hive的表是稠密型,即定义多少列,每一行有存储固定列数的数据。
- Hive使用Hadoop来分析处理数据,而Hadoop系统是批处理系统,因此不能保证处理的低延迟问题。
- Hive不提供row-level的更新,它适用于大量append-only数据集(如日志)的批处理任务。
- Hive提供完成的SQL实现,通常被用来做一些基于历史数据的挖掘、分析。
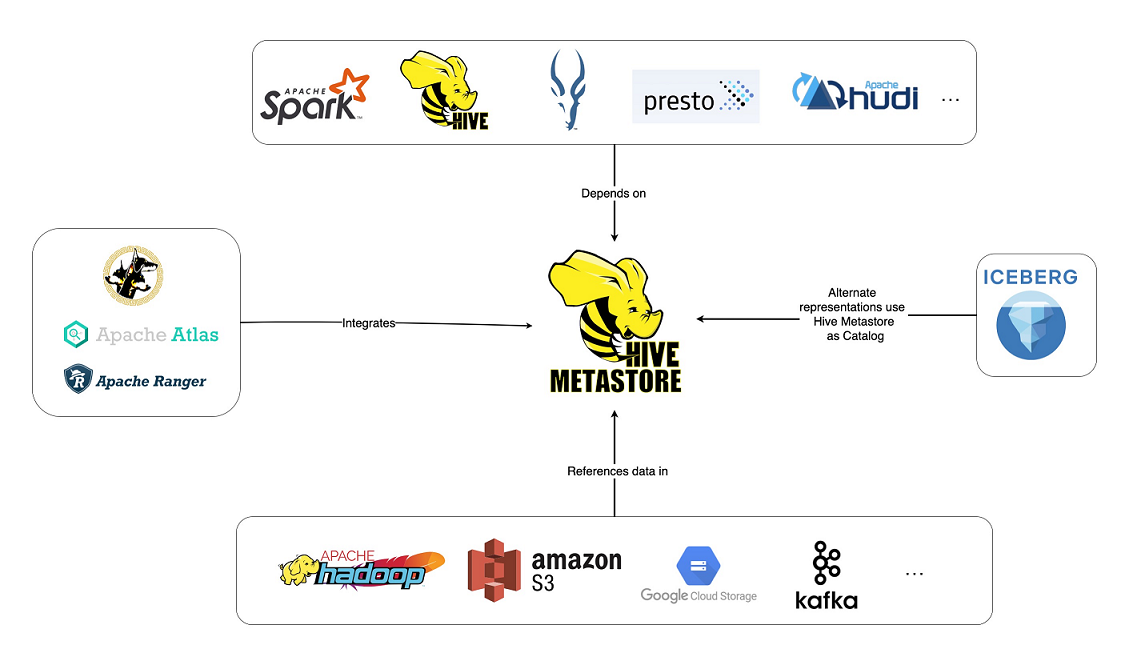
<font color="blue">**Hive Metastore (HMS)**</font> 是关系数据库中 Hive 表和分区 元数据的中央存储库,并为客户端**(包括 Hive、Impala 和 Spark)**提供使用 Metastore 服务 API 访问此信息的能力。它已成为利用各种开源软件(例如 Apache Spark 和 Presto)的数据湖的构建块。事实上,整个工具生态系统(开源工具和其他工具)都是围绕 Hive Metastore 构建的,此图展示了其中一些工具。
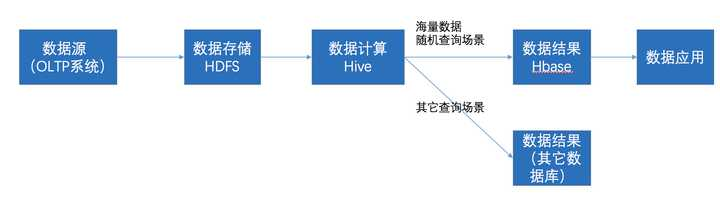
Hive和HBase的关系
HBase和Hive在大数据架构中处在不同位置,HBase主要解决实时数据查询问题,Hive主要解决数据处理和计算问题,一般是配合使用。
在大数据架构中,Hive和HBase是协作关系,数据流一般如下图:
- 通过ETL工具将数据源抽取到HDFS存储;
- 通过Hive清洗、处理和计算原始数据;
- HIve清洗处理后的结果,如果是面向海量数据随机查询场景的可存入HBase
- 数据应用从HBase查询数据;
Impala
Impala是用于处理存储在Hadoop集群中的大量数据的MPP(大规模并行处理)SQL查询引擎。 它是一个用C ++和Java编写的开源软件。与其他Hadoop的SQL引擎相比,它提供了高性能和低延迟。
优点
- 支持JDBC/ODBC远程访问,支持SQL查询,快速查询大数据。
- 无需转换为MR,直接读取HDFS数据。
- 支持Data Local,可以对已有数据进行查询,减少数据的加载,转换。
- 支持列式存储,多种存储格式可以选择(Parquet, Text, Avro, RCFile, SequeenceFile)。
- 可以与Hive配合使用,兼容HiveSQL, 可对hive数据直接做数据分析。
- 基于内存进行计算,能够对PB级数据进行交互式实时查询、分析。
缺点
- 不支持用户定义函数UDF。
- 不支持text域的全文搜索。
- 不支持Transforms。
- 不支持查询期的容错。(发生故障,则直接返回错误)
- 对内存要求高。
- 完全依赖于hive。
- 实践过程中 分区超过1w 性能严重下降。
- Impala不提供任何对序列化和反序列化的支持。
- Impala只能读取文本文件,而不能读取自定义二进制文件。
- 每当新的记录/文件被添加到HDFS中的数据目录时,该表需要被刷新。
Impala和关系数据库
| Impala | 关系型数据库 |
|---|---|
| Impala使用类似于HiveQL的类似SQL的查询语言 | 关系数据库使用SQL语言 |
| 在Impala中,您无法更新或删除单个记录 | 在关系数据库中,可以更新或删除单个记录 |
| Impala不支持事务 | 关系数据库支持事务 |
| Impala不支持索引 | 关系数据库支持索引 |
| Impala存储和管理大量数据(PB) | 与Impala相比,关系数据库处理的数据量较少(TB) |
Impala与hive
相同点
- 数据储存:使用相同的数据存储池,都可以将数据的储存在HDFS或HBase中。
- 元数据:两者使用相同的元数据
- SQL解释处理:比较相似的就是都是通过词法分析生成执行计划。
- 查询计划树
不同点
- 执行计划
hive依赖于MapReduce执行框架,执行计划分成map->shuffle-reduce->…的模型。如果是一个Query则会有很多的写中间结果,由于MapReduce的执行特点,MapReudce任务的开启过程会增加过多的时间
Impala将执行计划表现为一颗完整的执行计划树,Impala将所有的执行计划分发到Impala进行查询执行,避免了MR中sort和shuffle过程中的时间浪费。 - 数据流
hive:采用push推的方式,将每次计算的结果都push达到下一个节点。
Impala:采用pull拉取的方式,将本节点需要的结果从上一个节点执行完的结果中进行pull拉取。 - 内存使用
Hive: 在执行过程中如果内存放不下所有数据,则会使用外存,以保证Query能顺序执行完。每一轮MapReduce结束,中间结果也会写入HDFS中,同样由于MapReduce执行架构的特性,shuffle过程也会有写本地磁盘的操作。
Impala: 在遇到内存放不下数据时,当前版本0.1是直接返回错误,而不会利用外存,以后版本应该会进行改进。这使用得Impala目前处理Query会受到一定的限制,最好还是与Hive配合使用。Impala在多个阶段之间利用网络传输数据,在执行过程不会有写磁盘的操作(insert除外) - 调度
hive任务调度依赖于hadoop的调度策略
Impala调度由自己完成,目前只有一种调度器,simple schedule,它会尽量满足数据的局部性,扫描数据的进程尽量靠近数据本身所在的节点服务器。调度器目前还比较简单,在Simple Scheduler::GetBackend中可以看到,现在还没有考虑负载,网络IO状况等因素进行调度。但目前Impala已经有对执行过程的性能统计分析,应该以后版本会利用这些统计信息进行调度吧。 - 容错
Hive依赖于Hadoop的容错能力。
Impalad:在查询过程中,没有容错逻辑,如果在执行过程中,发生故障,则直接返回错误(这与Impalad的设计有关,因为Impala定位于实时查询,一次查询失败,再查询一次就好,再查一次的成本很低)。但从整体来看,Impala是能很好的容错,所有的Impalad是对等的结构,用户可以向任何一个Impalad提交查询,如果一个Impalad失效,其上正在运行的所有Query都将失败,但用户可以重新提交查询由其它Impalad代替执行,不会影响服务。对于State Store目前只有一个,但当State Store失效,也不会影响服务,因为每个Impala都同步了State store的信息。只是不能再次更新集群的状态了。有可能会将执行计划分配给已经失效的Impalad执行。 - 适用场景
Hive:复杂的批处理查询任务,数据转换任务。
Impala:实时数据分析,因为不支持UDF,能处理的问题有一定的限制,与Hive配合使用,对Hive的结果数据集进行实时分析。
Hive,HBase和Impala
| HBase | Hive | Impala |
|---|---|---|
| HBase是基于Apache Hadoop的宽列存储数据库。 它使用BigTable的概念。 | Hive是一个数据仓库软件。 使用它,我们可以访问和管理基于Hadoop的大型分布式数据集。 | Impala是一个管理,分析存储在Hadoop上的数据的工具。 |
| HBase的数据模型是宽列存储。 | Hive遵循关系模型。 | Impala遵循关系模型。 |
| HBase是使用Java语言开发的。 | Hive是使用Java语言开发的。 | Impala是使用C ++开发的。 |
| HBase的数据模型是无模式的。 | Hive的数据模型是基于模式的。 | Impala的数据模型是基于模式的。 |
| HBase提供Java,RESTful和Thrift API。 | Hive提供JDBC,ODBC,Thrift API。 | Impala提供JDBC和ODBC API。 |
| 支持C,C#,C ++,Groovy,Java PHP,Python和Scala等编程语言。 | 支持C ++,Java,PHP和Python等编程语言。 | Impala支持所有支持JDBC / ODBC的语言。 |
| HBase提供对触发器的支持。 | Hive不提供任何触发器支持。 | Impala不提供对触发器的任何支持。 |