Impala Sql优化案例分享
分布式执行
以⼀个SQL例⼦来展示查询计划
1 | select |
单机执行计划
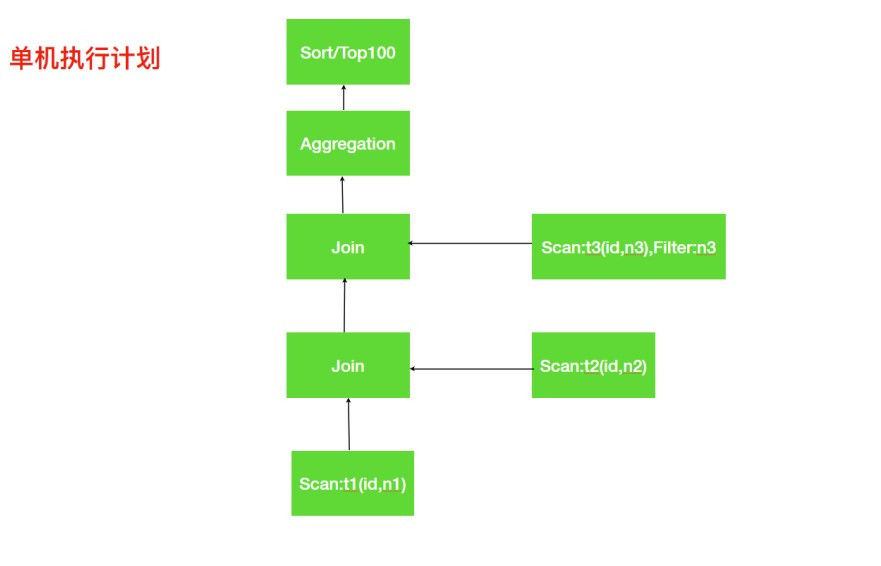
分析上⾯的单机执⾏计划,第⼀步先去扫描 t1 表中需要的数据,如果数据⽂件存储是列式存储我们可以便利的扫描到所需的列 id, n1; 接着需要与 t2 表进⾏ Join 操作,扫描 t2 表与 t1 表类似获取到所需数据列 id, n2。t1 与 t2 表进⾏关联执行 join 操作,关联之后再与 t3 表进⾏关联,这⾥会使⽤谓词下推扫描 t3 表只取 join 所需数据;关联三个表得到数据后,对 group by 进⾏相应的 aggregation 操作,最终是排序取出指定数量的数据返回。
这里由于是在一台机器上完成上述过程,所以逻辑上还是比较直观的。但是倘若所查询的 T1 和 T2 的数据都比较大,无法在一台机器上存储,或者单机执行效率太慢,这个时候就需要分布式并行执行计划来执行上述流程。
分布式并行执行计划
所谓的分布式并行化执行计划,就是在单机执行计划基础之上结合数据分布式存储的特点,按照任务的计要求把单机执行计划拆分为多段子任务,每个子任务都是可以并行执行的。上面的单机执行计划转为分布式并行执行计划如下图所示:
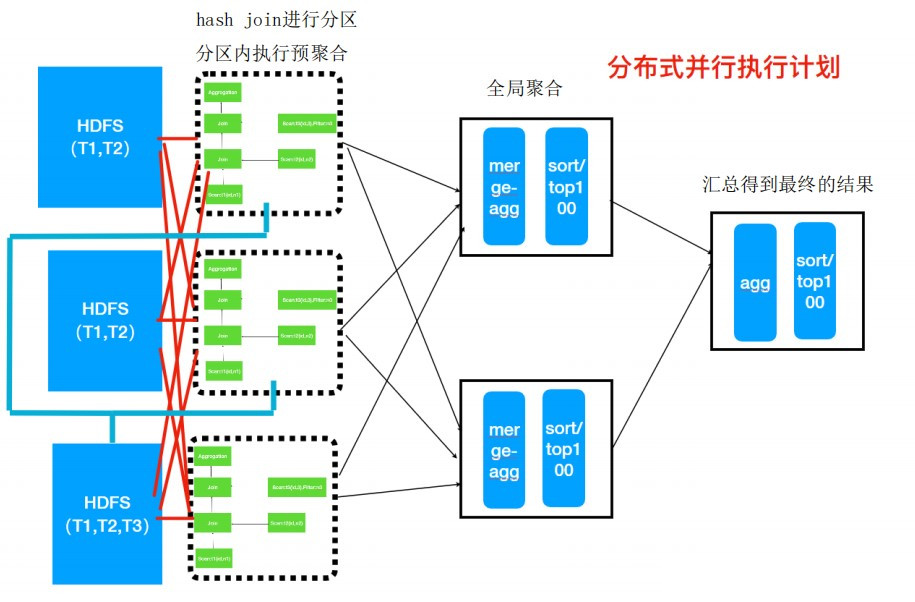
整体流程
一、Hash join分区
首先底层仍然先执行的是数据间的 join 操作。这里我们假设 T1 表和 T2 表是大表,分布在三个节点上(三台机器上)。而 T3 表是小表,只存储在第三个节点。此时为了做表之间数据的 Join 操作,可以想到需要将相同 id 字段的数据汇总到一起,这样才能进行拼接。 为了实现该过程,分布式执行计划会首先根据 T1 和 T2 两个大表中数据的 id 字段进行 hash join,采取的公式类似于:
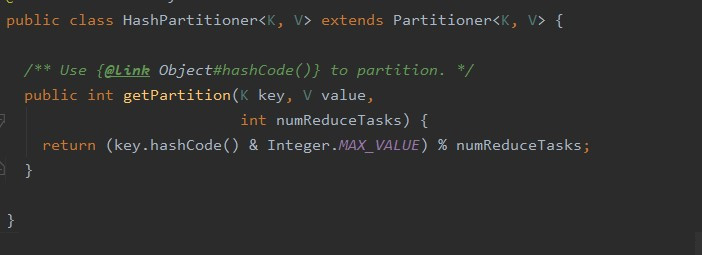
这个是 MapReduce 中 HashPartitioner 类中的方法。可以看出上式的分区结果只与 key 值的 hashCode 有关。这里 id 字段是 int 类型,则 hashCode 就是其本身,所以通过上式,就可以实现将T1和T2表中相同id字段的数据划分到同一分区中。(这里要注意的是,不是id为1的字段进入一个分区,2、3、4、5…都各进入一个分区,通过上式可以看出是对分区大小取%的操作,图中分区大小是3,因此id为1,4,7…的数据进入同一分区。)
同时要注意的是,对于 T3 表与 T1、T2 表数据的关联采用的不是 hash join,而是利用 Broadcast 来进行 join。 因为 T3 表的数据量较小,如果仍然采用 hash join 的话,就需要在 T1 表和 T2 表通过 hash join 分区后,再利用 hash join 与 T3 表重复执行一遍上述分区流程。这样增加了不同节点间网络传输的开销,也降低了执行效率。因此,对于小表,分布式执行计划采用的方法是利用广播机制,将该 T3 表直接分发到三个节点上。这样每个节点在执行完 T1 表与 T2 表的关联后,就可以直接在本机上执行与 T3 表的关联。
通过上面的步骤,就可以保证对于 T1 表和 T2 表,id 字段相同的数据进入到同一分区中进行 join 操作,然后再与本机的 T3 表进行 join 操作。即完成了 sql 中的
1 | from t1 |
二、分区内预聚合
这一步相当于执行 group by 的步骤。因为在分区时每条数据都带着各自的字段,也就包含着 n1, n2 的数据,所以此时在每个分区中,就可以对该分区内的数据按照 n1, n2 的值,执行 group by 操作进行一个局部的预聚合。
三、全局聚合
通过上述操作可以得到分区内的局部预聚合。但此时,条件相同的 n1, n2 可能分散在各个分区中(因为最初是按 id 字段分区的)。因此还需要一个全局的聚合,把所有 hash 结果相同的 <n1, n2> 进行汇总,这样才能得到最后的结果。因此,此时各个分区中预聚合(group by)后的数据会根据该组的 <n1, n2> 值再利用 hash join 进行分区,使得对 <n1, n2> 的 hash 值相同的数据组发送到同一分区中(此时数据量经过预聚合后已经变小了,所以就可以减少分区数,图上减少为 2 个)。这样在每个分区中每个组内的数据都是包含了所有 <n1, n2> Hash 值相等的结果,也即可以得到 SQL 查询语句中 group by 的最终结果(相当于原查询语句中,group by n1, n2 后所有应该进入同一分组中的数据)。
四、局部TopN
除了上述过程可以并行外,还有其它操作也可以并行吗?由于原SQL语句有 order by limit 操作,所以其实还可以在全局聚合后执行局部的 order by limit 操作。由于order by 操作是对得到的最终结果进行 order by,因此,这里就可以在每个分区进行全局聚合后,对得到的 count(1) as c 进行 order by limit 操作,得到局部的 Top100 的结果。这样同样减少了网络间传输的数据量,同时也体现了并行执行的特点。
五、全局TopN
最后,就是将所有的数据进行汇总,然后执行全局的order by limit 操作,就可以得到最终的结果。
整体的分布式并行执行计划流程图如下图所示:
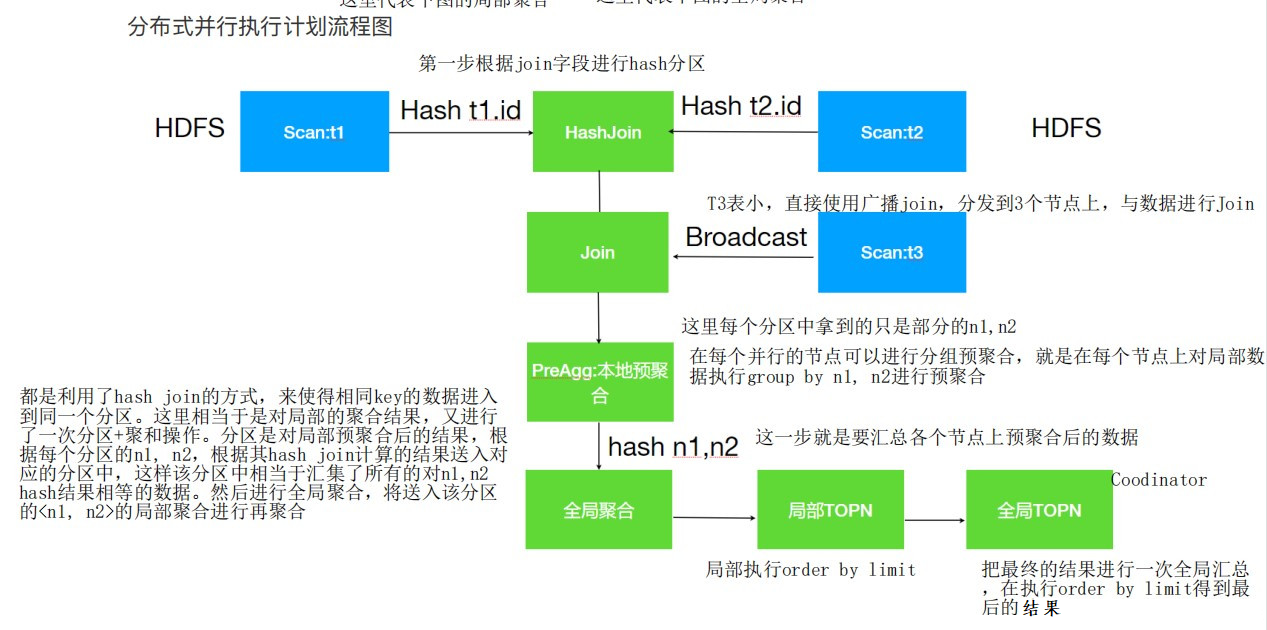
各部分的具体操作就如上述流程介绍中所示。对上述流程的总结如下:
- T1 和 T2 使⽤ Hash join,此时需要按照 id 的值分别将 T1 和 T2 分散到不同的进程,但是相同的 id 会散列到相同的进程,这样每⼀个 Join 之后是全部数据的⼀部分
- T1 与 T2 Join之后的结果数据再与 T3 表进⾏ Join,此时 T3 表采⽤ Broadcast ⽅式把⾃⼰全部数据(id列)⼴播到需要的节点上
- T1, T2, T3 Join之后再根据 Group by 执⾏本地的预聚合,每⼀个节点的预聚合结果只是最终结果的⼀部分(不同的节点可能存在相同的 group by 的值),需要再进⾏⼀次全局的聚合。
- 全局的聚合同样需要并⾏,则根据聚合列进⾏Hash分散到不同的节点执⾏ Merge 运算(其实仍然是⼀次聚合运算),⼀般情况下为了较少数据的⽹络传输, 会选择之前本地聚合节点做全局聚合⼯作。
- 通过全局聚合之后,相同的 key 只存在于⼀个节点,然后对于每⼀个节点进⾏排序和 TopN 计算,最终将每⼀个全局聚合节点的结果返回进⾏合并、排序、limit计算,返回结果给⽤户。
连接查询优化
一文读懂Impala统计信息相关知识 、 使用Impala hint加速SQL查询 、 Impala简明调优手册
方式一
优化连接最简单的方式就是使用 COMPUTE STATS 命令搜集所以参与关联表的统计信息,让 Impala 根据每个表的大小、列的非重复值个数等相关信息自动优化查询。为保证统计信息的准确性,我们需要在对表 INSERT、LOAD DATA 或者添加分区等操作之后及时执行 COMPUTE STATS 命令搜集统计信息。
Impala查询优化器根据表的绝对大小和相对大小为连接查询选择不同的关联技术,它提供了两种连接方式:
- 默认的连接方式是 Broadcast 连接,当右表比左表小时,它的内容会被发送到所有执行查询的节点上。
- 另一种连接方式是 partitioned 连接,它使用大小差不太多的大表关联。使用此种方式关联,为了保证关联操作可以并行执行,每个表的一部分数据都会被发送到不同节点上,最后各节点分别对传送过来的数据并行处理。
具体Impala优化器选择哪种连接方式,完全依赖于通过 COMPUTE STATS 搜集的表统计信息。为了确认表的连接策略,我们可以对一个特定的查询执行 EXPLAIN 语句。如果通过基准测试我们可以确认一种连接方式比另一种连接方式效率更高,也可以通过 Hint 的方式手动指定需要的连接方式。
方式二
当统计信息不可用时如何关联
如果参与关联的表的统计信息不可用,而且 Impala 自动选择的连接顺序效率很低,我们可以在 SELECT 关键字之后使用 STRAIGHT_JOIN 关键字手动指定连接的顺序。
如果参与关联的某些表的统计信息还是可用的,Impala会根据存在统计信息的表重新生成连接顺序。有统计信息的表会被放置在连接顺序的最左端,并根据表的基数和规模降序排列。而没有统计信息的表被作为空表对待,总是放在连接顺序的最右端。
方式三
使用 STRAIGHT_JOIN 覆盖连接顺序
如果关联查询由于统计信息不可用、或过期、或者数据分布等问题导致效率低下,我们可以通过指定STRAIGHT_JOIN关键字改变连接顺序。使用该关键字后,关联查询将不会使用 Impala 查询优化器自动生成的连接顺序,而是使用查询中表出现的先后顺序作为关联的顺序。对于手动指定连接顺序的查询,我们可能需要根据情况对连接顺序进行微调,比如有四张表分别为BIG、MEDIUM、SMALL、TINY,那连接顺序可以调整为:BIG、TINY、SMALL、MEDIUM。
如下示例中,表 BIG 经过过滤实际上产生了一个非常小的结果集,而 Impala 仍然把它作为最大的表对待放在连接顺序的最左侧。为了改变优化器错误的判断,我们使用 STRAIGHT_JOIN 改变连接的顺序,把 BIG 表放到了联机顺序的最右侧:
1 | select straight_join x |
ImpalaSQL优化思路
- 大表和小表JOIN时,确保大表在左侧,小表在右侧(Impala 会广播小表到所有节点);
- 有四张表分别为BIG、MEDIUM、SMALL、TINY,那连接顺序可以调整为:BIG、TINY、SMALL、MEDIUM。