35基础篇-Trie树:如何实现搜索引擎的搜索关键词提示功能?
搜索引擎的搜索关键词提示功能,我想你应该不陌生吧?为了方便快速输入,当你在搜索引擎的搜索框中,输入要搜索的文字的某一部分的时候,搜索引擎就会自动弹出下拉框,里面是各种关键词提示。你可以直接从下拉框中选择你要搜索的东西,而不用把所有内容都输入进去,一定程度上节省了我们的搜索时间。
搜索引擎的搜索关键词提示功能,我想你应该不陌生吧?为了方便快速输入,当你在搜索引擎的搜索框中,输入要搜索的文字的某一部分的时候,搜索引擎就会自动弹出下拉框,里面是各种关键词提示。你可以直接从下拉框中选择你要搜索的东西,而不用把所有内容都输入进去,一定程度上节省了我们的搜索时间。
上一节我们讲了BM算法,尽管它很复杂,也不好理解,但却是工程中非常常用的一种高效字符串匹配算法。有统计说,它是最高效、最常用的字符串匹配算法。不过,在所有的字符串匹配算法里,要说最知名的一种的话,那就非KMP算法莫属。很多时候,提到字符串匹配,我们首先想到的就是KMP算法。
尽管在实际的开发中,我们几乎不大可能自己亲手实现一个KMP算法。但是,学习这个算法的思想,作为让你开拓眼界、锻炼下逻辑思维,也是极好的,所以我觉得有必要拿出来给你讲一讲。不过,KMP算法是出了名的不好懂。我会尽力把它讲清楚,但是你自己也要多动动脑子。
实际上,KMP算法跟BM算法的本质是一样的。上一节,我们讲了好后缀和坏字符规则,今天,我们就看下,如何借助上一节BM算法的讲解思路,让你能更好地理解KMP算法?
KMP算法是根据三位作者(D.E.Knuth,J.H.Morris和V.R.Pratt)的名字来命名的,算法的全称是Knuth Morris Pratt算法,简称为KMP算法。
KMP算法的核心思想,跟上一节讲的BM算法非常相近。我们假设主串是a,模式串是b。在模式串与主串匹配的过程中,当遇到不可匹配的字符的时候,我们希望找到一些规律,可以将模式串往后多滑动几位,跳过那些肯定不会匹配的情况。
还记得我们上一节讲到的好后缀和坏字符吗?这里我们可以类比一下,在模式串和主串匹配的过程中,把不能匹配的那个字符仍然叫作坏字符,把已经匹配的那段字符串叫作好前缀。
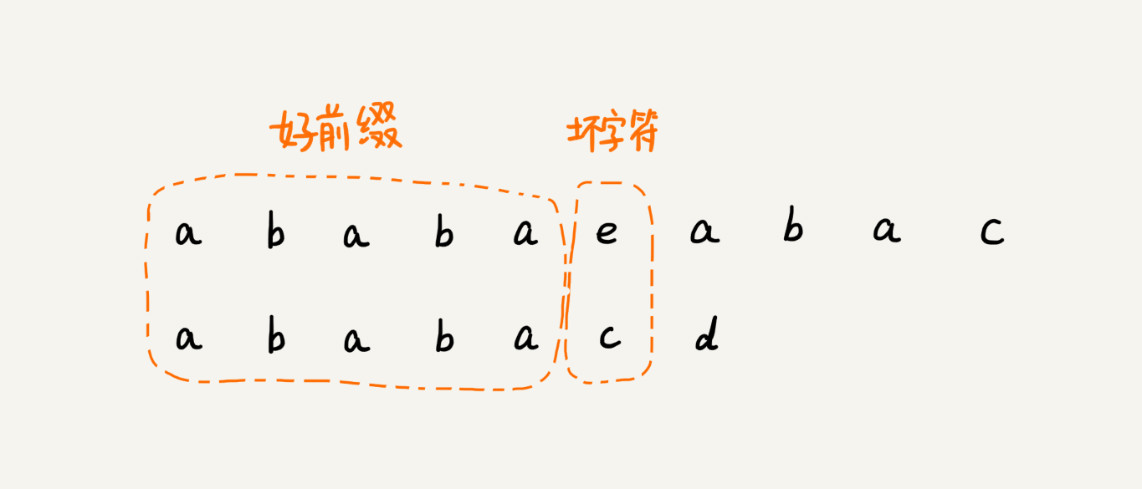
当遇到坏字符的时候,我们就要把模式串往后滑动,在滑动的过程中,只要模式串和好前缀有上下重合,前面几个字符的比较,就相当于拿好前缀的后缀子串,跟模式串的前缀子串在比较。这个比较的过程能否更高效了呢?可以不用一个字符一个字符地比较了吗?
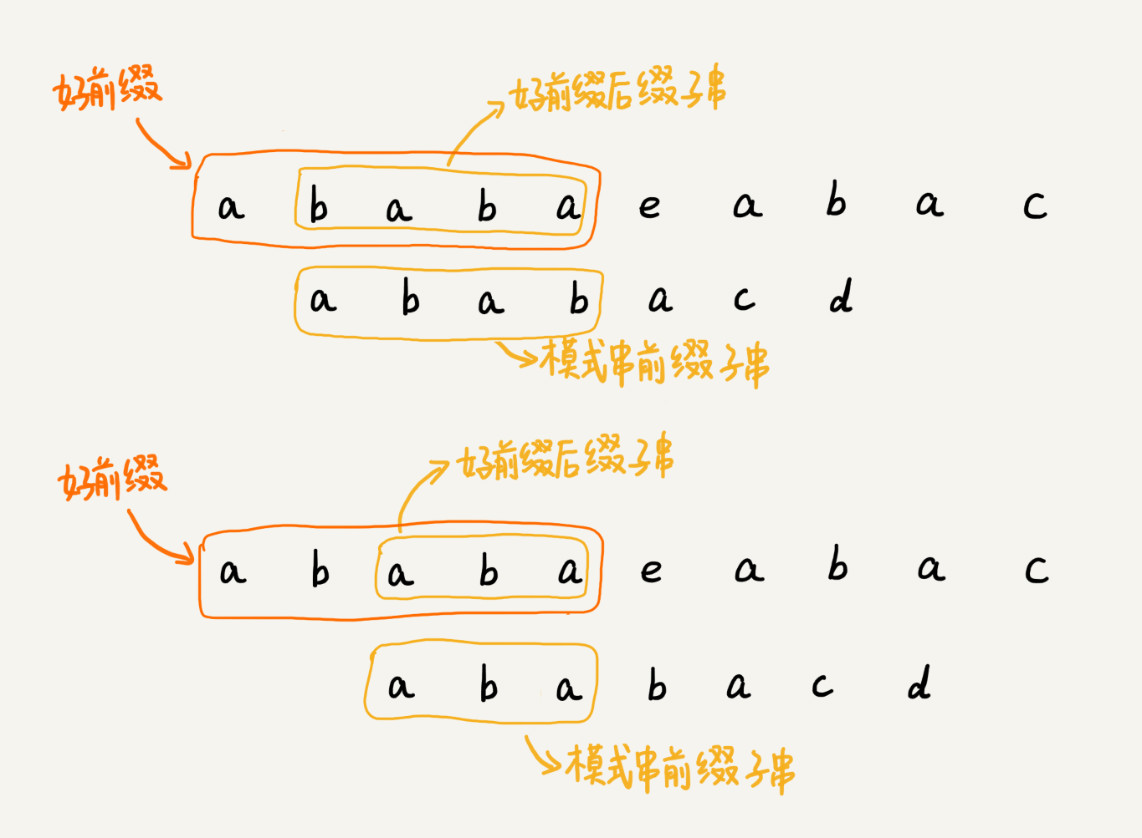
KMP算法就是在试图寻找一种规律:在模式串和主串匹配的过程中,当遇到坏字符后,对于已经比对过的好前缀,能否找到一种规律,将模式串一次性滑动很多位?
我们只需要拿好前缀本身,在它的后缀子串中,查找最长的那个可以跟好前缀的前缀子串匹配的。假设最长的可匹配的那部分前缀子串是{v},长度是k。我们把模式串一次性往后滑动j-k位,相当于,每次遇到坏字符的时候,我们就把j更新为k,i不变,然后继续比较。

为了表述起来方便,我把好前缀的所有后缀子串中,最长的可匹配前缀子串的那个后缀子串,叫作最长可匹配后缀子串;对应的前缀子串,叫作最长可匹配前缀子串。

如何来求好前缀的最长可匹配前缀和后缀子串呢?我发现,这个问题其实不涉及主串,只需要通过模式串本身就能求解。所以,我就在想,能不能事先预处理计算好,在模式串和主串匹配的过程中,直接拿过来就用呢?
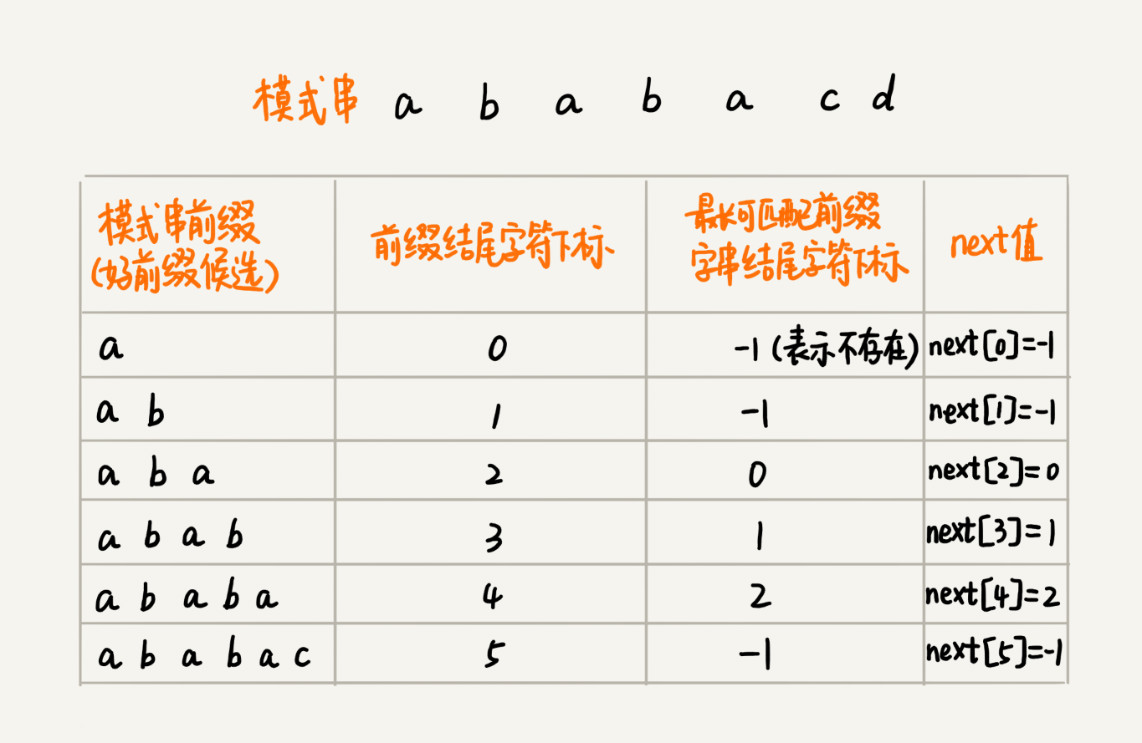
类似BM算法中的bc、suffix、prefix数组,KMP算法也可以提前构建一个数组,用来存储模式串中每个前缀(这些前缀都有可能是好前缀)的最长可匹配前缀子串的结尾字符下标。我们把这个数组定义为next数组,很多书中还给这个数组起了一个名字,叫失效函数(failure function)。
数组的下标是每个前缀结尾字符下标,数组的值是这个前缀的最长可以匹配前缀子串的结尾字符下标。这句话有点拗口,我举了一个例子,你一看应该就懂了。
有了next数组,我们很容易就可以实现KMP算法了。我先假设next数组已经计算好了,先给出KMP算法的框架代码。
1 | // a, b分别是主串和模式串;n, m分别是主串和模式串的长度。 |
KMP算法的基本原理讲完了,我们现在来看最复杂的部分,也就是next数组是如何计算出来的?
当然,我们可以用非常笨的方法,比如要计算下面这个模式串b的next[4],我们就把b[0, 4]的所有后缀子串,从长到短找出来,依次看看,是否能跟模式串的前缀子串匹配。很显然,这个方法也可以计算得到next数组,但是效率非常低。有没有更加高效的方法呢?

这里的处理非常有技巧,类似于动态规划。不过,动态规划我们在后面才会讲到,所以,我这里换种方法解释,也能让你听懂。
我们按照下标从小到大,依次计算next数组的值。当我们要计算next[i]的时候,前面的next[0],next[1],……,next[i-1]应该已经计算出来了。利用已经计算出来的next值,我们是否可以快速推导出next[i]的值呢?
如果next[i-1]=k-1,也就是说,子串b[0, k-1]是b[0, i-1]的最长可匹配前缀子串。如果子串b[0, k-1]的下一个字符b[k],与b[0, i-1]的下一个字符b[i]匹配,那子串b[0, k]就是b[0, i]的最长可匹配前缀子串。所以,next[i]等于k。但是,如果b[0, k-1]的下一字符b[k]跟b[0, i-1]的下一个字符b[i]不相等呢?这个时候就不能简单地通过next[i-1]得到next[i]了。这个时候该怎么办呢?
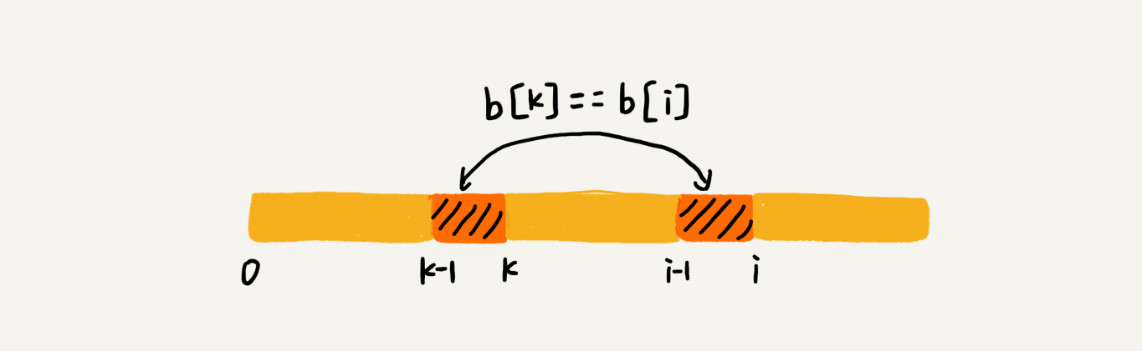
我们假设b[0, i]的最长可匹配后缀子串是b[r, i]。如果我们把最后一个字符去掉,那b[r, i-1]肯定是b[0, i-1]的可匹配后缀子串,但不一定是最长可匹配后缀子串。所以,既然b[0, i-1]最长可匹配后缀子串对应的模式串的前缀子串的下一个字符并不等于b[i],那么我们就可以考察b[0, i-1]的次长可匹配后缀子串b[x, i-1]对应的可匹配前缀子串b[0, i-1-x]的下一个字符b[i-x]是否等于b[i]。如果等于,那b[x, i]就是b[0, i]的最长可匹配后缀子串。
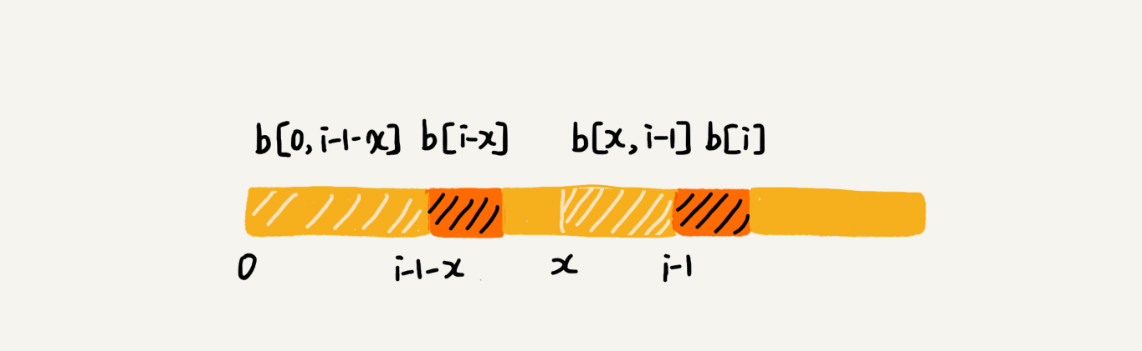
可是,如何求得b[0, i-1]的次长可匹配后缀子串呢?次长可匹配后缀子串肯定被包含在最长可匹配后缀子串中,而最长可匹配后缀子串又对应最长可匹配前缀子串b[0, y]。于是,查找b[0, i-1]的次长可匹配后缀子串,这个问题就变成,查找b[0, y]的最长匹配后缀子串的问题了。
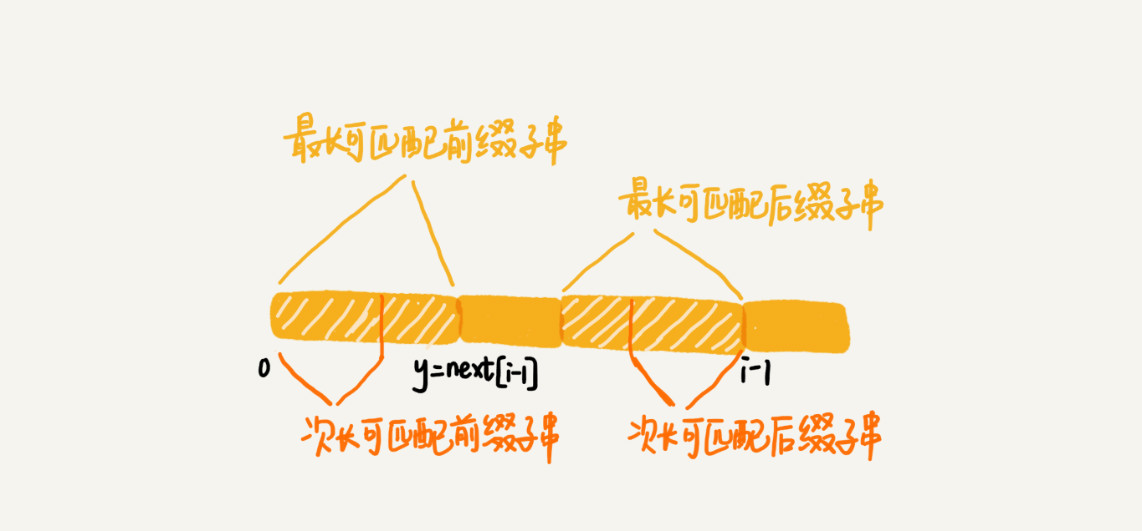
按照这个思路,我们可以考察完所有的b[0, i-1]的可匹配后缀子串b[y, i-1],直到找到一个可匹配的后缀子串,它对应的前缀子串的下一个字符等于b[i],那这个b[y, i]就是b[0, i]的最长可匹配后缀子串。
前面我已经给出KMP算法的框架代码了,现在我把这部分的代码也写出来了。这两部分代码合在一起,就是整个KMP算法的代码实现。
1 | // b表示模式串,m表示模式串的长度 |
KMP算法的原理和实现我们就讲完了,我们现在来分析一下KMP算法的时间、空间复杂度是多少?
空间复杂度很容易分析,KMP算法只需要一个额外的next数组,数组的大小跟模式串相同。所以空间复杂度是O(m),m表示模式串的长度。
KMP算法包含两部分,第一部分是构建next数组,第二部分才是借助next数组匹配。所以,关于时间复杂度,我们要分别从这两部分来分析。
我们先来分析第一部分的时间复杂度。
计算next数组的代码中,第一层for循环中i从1到m-1,也就是说,内部的代码被执行了m-1次。for循环内部代码有一个while循环,如果我们能知道每次for循环、while循环平均执行的次数,假设是k,那时间复杂度就是O(k*m)。但是,while循环执行的次数不怎么好统计,所以我们放弃这种分析方法。
我们可以找一些参照变量,i和k。i从1开始一直增加到m,而k并不是每次for循环都会增加,所以,k累积增加的值肯定小于m。而while循环里k=next[k],实际上是在减小k的值,k累积都没有增加超过m,所以while循环里面k=next[k]总的执行次数也不可能超过m。因此,next数组计算的时间复杂度是O(m)。
我们再来分析第二部分的时间复杂度。分析的方法是类似的。
i从0循环增长到n-1,j的增长量不可能超过i,所以肯定小于n。而while循环中的那条语句j=next[j-1]+1,不会让j增长的,那有没有可能让j不变呢?也没有可能。因为next[j-1]的值肯定小于j-1,所以while循环中的这条语句实际上也是在让j的值减少。而j总共增长的量都不会超过n,那减少的量也不可能超过n,所以while循环中的这条语句总的执行次数也不会超过n,所以这部分的时间复杂度是O(n)。
所以,综合两部分的时间复杂度,KMP算法的时间复杂度就是O(m+n)。
KMP算法讲完了,不知道你理解了没有?如果没有,建议多看几遍,自己多思考思考。KMP算法和上一节讲的BM算法的本质非常类似,都是根据规律在遇到坏字符的时候,把模式串往后多滑动几位。
BM算法有两个规则,坏字符和好后缀。KMP算法借鉴BM算法的思想,可以总结成好前缀规则。这里面最难懂的就是next数组的计算。如果用最笨的方法来计算,确实不难,但是效率会比较低。所以,我讲了一种类似动态规划的方法,按照下标i从小到大,依次计算next[i],并且next[i]的计算通过前面已经计算出来的next[0],next[1],……,next[i-1]来推导。
KMP算法的时间复杂度是O(n+m),不过它的分析过程稍微需要一点技巧,不那么直观,你只要看懂就好了,并不需要掌握,在我们平常的开发中,很少会有这么难分析的代码。
至此,我们把经典的单模式串匹配算法全部讲完了,它们分别是BF算法、RK算法、BM算法和KMP算法,关于这些算法,你觉得什么地方最难理解呢?
欢迎留言和我分享,也欢迎点击“请朋友读”,把今天的内容分享给你的好友,和他一起讨论、学习。
文本编辑器中的查找替换功能,我想你应该不陌生吧?比如,我们在Word中把一个单词统一替换成另一个,用的就是这个功能。你有没有想过,它是怎么实现的呢?
当然,你用上一节讲的BF算法和RK算法,也可以实现这个功能,但是在某些极端情况下,BF算法性能会退化的比较严重,而RK算法需要用到哈希算法,设计一个可以应对各种类型字符的哈希算法并不简单。
对于工业级的软件开发来说,我们希望算法尽可能的高效,并且在极端情况下,性能也不要退化的太严重。那么,对于查找功能是重要功能的软件来说,比如一些文本编辑器,它们的查找功能都是用哪种算法来实现的呢?有没有比BF算法和RK算法更加高效的字符串匹配算法呢?
今天,我们就来学习BM(Boyer-Moore)算法。它是一种非常高效的字符串匹配算法,有实验统计,它的性能是著名的KMP算法的3到4倍。BM算法的原理很复杂,比较难懂,学起来会比较烧脑,我会尽量给你讲清楚,同时也希望你做好打硬仗的准备。好,现在我们正式开始!
从今天开始,我们来学习字符串匹配算法。字符串匹配这样一个功能,我想对于任何一个开发工程师来说,应该都不会陌生。我们用的最多的就是编程语言提供的字符串查找函数,比如Java中的indexOf(),Python中的find()函数等,它们底层就是依赖接下来要讲的字符串匹配算法。
字符串匹配算法很多,我会分四节来讲解。今天我会讲两种比较简单的、好理解的,它们分别是:BF算法和RK算法。下一节,我会讲两种比较难理解、但更加高效的,它们是:BM算法和KMP算法。
这两节讲的都是单模式串匹配的算法,也就是一个串跟一个串进行匹配。第三节、第四节,我会讲两种多模式串匹配算法,也就是在一个串中同时查找多个串,它们分别是Trie树和AC自动机。
今天讲的两个算法中,RK算法是BF算法的改进,它巧妙借助了我们前面讲过的哈希算法,让匹配的效率有了很大的提升。那RK算法是如何借助哈希算法来实现高效字符串匹配的呢?你可以带着这个问题,来学习今天的内容。
上一节我们讲了图的表示方法,讲到如何用有向图、无向图来表示一个社交网络。在社交网络中,有一个六度分割理论,具体是说,你与世界上的另一个人间隔的关系不会超过六度,也就是说平均只需要六步就可以联系到任何两个互不相识的人。
一个用户的一度连接用户很好理解,就是他的好友,二度连接用户就是他好友的好友,三度连接用户就是他好友的好友的好友。在社交网络中,我们往往通过用户之间的连接关系,来实现推荐“可能认识的人”这么一个功能。今天的开篇问题就是,给你一个用户,如何找出这个用户的所有三度(其中包含一度、二度和三度)好友关系?
这就要用到今天要讲的深度优先和广度优先搜索算法。
微博、微信、LinkedIn这些社交软件我想你肯定都玩过吧。在微博中,两个人可以互相关注;在微信中,两个人可以互加好友。那你知道,如何存储微博、微信等这些社交网络的好友关系吗?
这就要用到我们今天要讲的这种数据结构:图。实际上,涉及图的算法有很多,也非常复杂,比如图的搜索、最短路径、最小生成树、二分图等等。我们今天聚焦在图存储这一方面,后面会分好几节来依次讲解图相关的算法。
搜索引擎的热门搜索排行榜功能你用过吗?你知道这个功能是如何实现的吗?实际上,它的实现并不复杂。搜索引擎每天会接收大量的用户搜索请求,它会把这些用户输入的搜索关键词记录下来,然后再离线地统计分析,得到最热门的Top 10搜索关键词。
那请你思考下,假设现在我们有一个包含10亿个搜索关键词的日志文件,如何能快速获取到热门榜Top 10的搜索关键词呢?
这个问题就可以用堆来解决,这也是堆这种数据结构一个非常典型的应用。上一节我们讲了堆和堆排序的一些理论知识,今天我们就来讲一讲,堆这种数据结构几个非常重要的应用:优先级队列、求Top K和求中位数。
我们今天讲另外一种特殊的树,“堆”($Heap$)。堆这种数据结构的应用场景非常多,最经典的莫过于堆排序了。堆排序是一种原地的、时间复杂度为$O(n\log n)$的排序算法。
前面我们学过快速排序,平均情况下,它的时间复杂度为$O(n\log n)$。尽管这两种排序算法的时间复杂度都是$O(n\log n)$,甚至堆排序比快速排序的时间复杂度还要稳定,但是,在实际的软件开发中,快速排序的性能要比堆排序好,这是为什么呢?
现在,你可能还无法回答,甚至对问题本身还有点疑惑。没关系,带着这个问题,我们来学习今天的内容。等你学完之后,或许就能回答出来了。
我们都知道,递归代码的时间复杂度分析起来很麻烦。我们在第12节《排序(下)》那里讲过,如何利用递推公式,求解归并排序、快速排序的时间复杂度,但是,有些情况,比如快排的平均时间复杂度的分析,用递推公式的话,会涉及非常复杂的数学推导。
除了用递推公式这种比较复杂的分析方法,有没有更简单的方法呢?今天,我们就来学习另外一种方法,借助递归树来分析递归算法的时间复杂度。
红黑树是一个让我又爱又恨的数据结构,“爱”是因为它稳定、高效的性能,“恨”是因为实现起来实在太难了。我今天讲的红黑树的实现,对于基础不太好的同学,理解起来可能会有些困难。但是,我觉得没必要去死磕它。
我为什么这么说呢?因为,即便你将左右旋背得滚瓜烂熟,我保证你过不几天就忘光了。因为,学习红黑树的代码实现,对于你平时做项目开发没有太大帮助。对于绝大部分开发工程师来说,这辈子你可能都用不着亲手写一个红黑树。除此之外,它对于算法面试也几乎没什么用,一般情况下,靠谱的面试官也不会让你手写红黑树的。
如果你对数据结构和算法很感兴趣,想要开拓眼界、训练思维,我还是很推荐你看一看这节的内容。但是如果学完今天的内容你还觉得懵懵懂懂的话,也不要纠结。我们要有的放矢去学习。你先把平时要用的、基础的东西都搞会了,如果有余力了,再来深入地研究这节内容。
好,我们现在就进入正式的内容。上一节,我们讲到红黑树定义的时候,提到红黑树的叶子节点都是黑色的空节点。当时我只是粗略地解释了,这是为了代码实现方便,那更加确切的原因是什么呢? 我们这节就来说一说。