MySQL_09性能分析工具的使用
性能分析工具的使用
性能分析工具的使用
索引的创建与设计原则
InnoDB数据存储结构
索引的数据结构
存储引擎
逻辑架构
用户与权限管理
Windows 和 Linux 版安装详细步骤。
微波:https://zh.wikipedia.org/zh-cn/%E5%BE%AE%E6%B3%A2
载波:https://zh.wikipedia.org/zh-cn/%E8%BD%BD%E6%B3%A2。
携带信息/信号的波形,它携带的方式是进行频率、幅度、相位间隔调制。
电磁波谱:https://zh.wikipedia.org/zh-cn/%E9%9B%BB%E7%A3%81%E6%B3%A2%E8%AD%9C
在电磁学里,电磁波谱包括电磁辐射所有可能的频率。一个物体的电磁波谱专指的是这物体所发射或吸收的电磁辐射(又称电磁波)的特征频率分布。
频段/波段:https://zh.wikipedia.org/zh-cn/%E6%B3%A2%E6%AE%B5、https://baike.baidu.com/item/%E9%A2%91%E6%AE%B5/10828844
波段是无线电通信频率中的一小段电磁波谱。
5G NR频段:https://zh.wikipedia.org/zh-cn/5G_NR%E9%A2%91%E6%AE%B5
信道:https://zh.wikipedia.org/zh-cn/%E4%BF%A1%E9%81%93
带宽/频宽/频带宽度:https://zh.wikipedia.org/zh-cn/%E5%B8%A6%E5%AE%BD、https://baike.baidu.com/item/%E4%BF%A1%E9%81%93%E5%B8%A6%E5%AE%BD/8780875
又叫”信道带宽”。信道包括模拟信道和数字信道。
指信号所占据的频带宽度。在被用来描述信道时,带宽是指能够有效通过该信道的信号的最大频带宽度。
对于模拟信号而言,带宽又称为频宽,以赫兹(Hz)为单位。对于数字信号而言,带宽是指单位时间内链路能够通过的数据量(单位bps),例如家庭网络带宽500Mbps。两者可通过香农定理互相转换。
模拟信道的带宽 W=f2-f1 其中f1是信道能够通过的最低频率,f2是信道能够通过的最高频率。
频率:https://zh.wikipedia.org/zh-cn/%E9%A0%BB%E7%8E%87
又称周率,是物理学上描述某具规律周期性的现象或事件,在每单位时间内(即每秒)重复发生的次数(周期数,即循环次数)。周期(T)的倒数。
频点:https://baike.baidu.com/item/%E9%A2%91%E7%82%B9/1358712
频点,指具体的绝对频率值。一般为调制信号的中心频率。频点是给固定频率的编号。
举个栗子,如果对频段进行编号,从1、2、3、4 … … 125,那么这些对固定频率的编号就是频点;
WIFI中的频段、信道、信道带宽、传输速率的理解:https://zhuanlan.zhihu.com/p/357339416
数据传输速率:简称传输速率,在电信领域是指在单位时间内在数据传输系统设备之间传送比特,字符,或者块的平均值。
信道带宽越大,传输速率越大。
频率越高,传输速率越高。
波速由传输介质决定(障碍物)。在室温下,声波在空气中的传播速度约为340m/s;电磁波在真空中传播的速度等于光速。
提供传输速率的技术
频分复用:https://zh.wikipedia.org/zh-cn/%E9%A2%91%E5%88%86%E5%A4%9A%E8%B7%AF%E5%A4%8D%E7%94%A8、https://www.cnblogs.com/cyyljw/p/6871946.html
MIMO:https://zh.wikipedia.org/zh-cn/MIMO
RAN(radio access network):无线接入网。提供用户设备和核心网之间的连接,将核心网和无线网络隔离开的无线接入网络。
Duplex mode:双工模式。双工(duplex), 指二台通信设备之间,允许有双向的数据传输。
Frequency:频段,在规定的两个界限频率之间的一段连续频率。对应类型 B1、B2、B3…(频段类型对照表)
频带:由规定它在频谱中位置的两个值(例如其上限频率和下限频率)来表示。例如B1为一个频段,B1+B3为两个频段。
Uplink:上行链路(UL)
Downlink:下行 (DL)
5G NR :5G NR(New Radio)是一个新的无线接入技术(RAT),由3GPP开发,用于第五代移动通信网络(5G)。它是5G网络空中接口的全球通用标准。
5G NR频段 、 5G NR frequency bands
5G风波:一个频段几百亿,美国为什么不上5G,高频段多数被军方使用。
高级长期演进技术 - LTE-Advanced简称LTE-A,在中国大陆称4G+
CA(Carrier aggregation):载波聚合。为了提供更高的业务速率,3GPP 在 LTE-Advanced 阶段提出下行1Gbit/s的速率要求,引入了载波聚合。通过将多个连续或非连续的载波(Component Carrier,简称CC)聚合成更大的带宽(最大100MHz)。上下行支持CA及上行支持CA和下行支持CA。
ENDC(EUTRA-NR Dual Connectivity):可以理解为 4G 和 5G 双连接的相互兼容。
E:表示 LTE 的 E-UTRA
N:表示 5G NR
Dual Connectivity:双连接
ENDC 允许用户设备连接到充当主节点的 LTE enodeB 和充当辅助节点的5G gnodeB。即可以使用4G频段充当5G锚点下载。
CA能力:1a(2R)↑+8b(2R)。1表示频段为band1,a表示一个band1,↑表示一个上行支持CA载波,8表示band8,b表示2个band8,该能力表示1个带有1个上行载波的band1和2个带有1个下行载波的band8
ENDC能力:B3a↑+N78a↑。B3表示band3,a表示一个band3,↑表示一个上行载波,N78表示NR频段78,a表示一个N78频段,该能力表示一个带有1个上行载波的N78和附带一个带有1个上行载波的B3锚点
a) B表示4G频段(LTE频段),N表示5G频段(NR频段)
b) 频段号后面的abcde表示载波数,a=1,b=2,c=2,d=3,e=4
c) 4G频段后带↑表示一个上行载波,↑↑表示两个上行载波
d) ENDC能力的4G频段后的↑位置表示锚点位置,两个↑不是锚点
e) 两个4G上行载波表示上行支持CA,所有LTE频段都包含下行载波,即下行支持CA
示例表名:PR01_XXX__666666,解析如下:
第1位(P)
第2位(R)
第3、4位(01)
PR(Public data Result table):公开数据结果表
LR(Local data Result table):本地数据结果表
OR():
LS():
1、由于MPP数据库对于表名长度有限制,整个数据流程中都会限制用户的表名长度不能超过50
2、每张数据表在数据管理里都有唯一主键tableid进行管理,不同阶段生成的同名表的tableid不一致。
DEV(Development):开发
SIT(system integration test):系统集成测试
UAT(User Acceptance Test):用户验收测试
PET(Performance Evaluation Test):性能评估测试(压测)
SIM(simulation):仿真
PROD(production):产品/正式/生产
MPP(massively parallel processing):规模并行处理(MPP,massively parallel processing)是多个处理器(processor)处理同一程序的不同部分时该程序的协调过程,工作的各处理器运用自身的操作系统(Operating System)和内存。大规模并行处理器一般运用通讯接口交流。在一些执行过程中,高达两百甚至更多的处理器为同一应用程序工作。数据通路的互连设置允许各处理器相互传递信息。一般来说,大规模并行处理(MPP)的建设很复杂,这需要掌握在各处理器间区分共同数据库和给各数据库分派工作的方法。大规模并行处理系统也叫做“松散耦合”或“无共享”系统。 一般认为,对于允许平行搜索大量数据库的应用程序,大规模并行处理(MPP,massively parallel processing)系统比对称式并行处理系统(SMP)更好。这些包括决策支持系统(decision support system)和数据仓库(data warehouse)应用程序。
PO(purchase order):采购订单
PR(peer review):同行评审
TBD(To Be Determined):待定
TBD(To be done):待确认
TBD(to be designed):待设计
eox 停止x
GA(general availability):软件版本周期是指计算机软件的发展及发布过程,从Pre-alpha(准预览版本)发展到Alpha(预览版本)、Beta(测试版本)、Released candidate (最终测试版本)至最后的Gold(完成版)。GA点在IPD过程里意味着产品可以批量交付给客户。
EOS(End of Service & Support):停止服务。
EOP(End of Production):停止生产。
EOM(End of Marketing):停止销售。
EOFS(End of Full Support):停止全面支持。版本EOFS之后,研发停止补丁版本开发。
PILOT:试点、试生产
DEVELOP:开发中
Business Continuity Management (BCM) 业务连续性管理
PLR(packet loss rate):丢包率是指测试中所丢失数据包数量占所发送数据包的比率。
RTT(round-trip time):RTT时延。RTT是网络中的一个重要的性能指标,表示从发送端发送数据开始,到发送端收到来自接收端的确认(接收端收到数据后便立即发送确认),总共经历的时延。
OMP(Outsourcer Management Platform):研发外包项目管理平台
OMP(Openness Management Platform):开放能力管理平台。企业互联网能力开放解决方案是一个为企业提供核心业务能力输出、支撑企业与外部中小合作伙伴进行增值业务合作的技术平台解决方案。方案以云PaaS的架构,面向企业运营、系统运维、合作伙伴以及最终用户,提供核心能力运营、系统自动化运维、外平台合作伙伴和最终用户自服务等多维支撑能力,助力企业在互联网领域进行业务拓展。
IBMS(Installed Base Management System):.存量数据管理系统。存量市场指的是由网上运行设备所形成的服务市场。增量市场指的是由新建设备所形成的服务市场。
DM(developed market):存量市场。由网上运行设备所形成的服务市场。
CTS(Cloud Trace Service):云审计服务
ICT(information and communications technology):信息和通信技术。信息和通讯技术是信息技术与通讯技术的融合,将消息传播的传送技术和信息的编码或解码,以及通信载体的传输方式相互融合。
GTS(Global Technical Service):全球技术服务、通用技术
UCD(user-centered design):以用户为中心的设计。一种设计方法,通过用户的有效参与来充分了解用户需求,从而满足用户要求。
OR(original requirement):OR流程。由一线及机关各体系人员向需求管理系统(RM)提交的服务产品需求,是站在客户角度描述的需求。原始需求一般包含需求来源、需求描述、价值评价等几大部分。
OR(offering requirement):产品需求。用户提出的超出合同技术建议书或产品规格说明书范围的需求。
BOQ(Bill of Quotation):报价单。报价单也叫配置清单,是销售配置的载体。当报价项对应华为编码时,配置清单为华为编码BOQ,即SBOQ;当报价项还对应客户编码时,配置清单除了SBOQ,还包括客户编码BOQ,即CBOQ。BOQ是华为(卖方/服务提供商)发送给客户的报价单,它描述了方案offering和客户需要付的价格。 在华为,由产品经理根据客户需求,拟制的产品配置报价清单。它是一个或多个产品配置清单的集合,其中可能包括的内容有:产品的配置清单,数量、单价、总价、本币价、折扣价、汇总表(L1/L2)等,产品内容包括了所有要提供给客户的报价项目,如:设备、服务(工程、培训)、散件、备板备件等信息;实际的BOQ是这些内容的全部或部分; 在客户接受了华为的报价并作为其设备(和、或服务)供应商后,客户将BOQ或者另外单独下PO,作为交付履行的产品或者服务的详细配置;如果客户采用客户的编码体系进行下单,华为需要根据相关内容转换成华为可以履行的BOQ。
BOQ(bill of quantities):工程量清单。工程量清单( Bill of Quantities )是一份将设计图纸季所采用的工料规格说明书的要求化为可以计算造价的一系列施工项目及数量的文件,便于投标者比价竞争。
rpd(requested packing date):要求交单日期,下单。用户订货
asd(actual shipping date):实际发货日期,发货,Shipment 。商家发货
ata(Actual Time of Arrival):实际到货时间
opportunity:机会点,要货,Demand
order data inventory(库存):订货,Order
BCM(Business Continuity Management):业务连续性管理
GTM(general topology manager):通用布局管理器
GTM(Global Transaction Manager):全局事务管理器
GTM(Go-to-Market):上市
BU(Business Unit):业务单元
PSP(Product Settlement Price):产品结算价。产品结算价是公司给试点代表处的产品批发价,是代表处的产品成本。
NEED:轻咨询方法
FBB(fixed broadband):固定宽带
MBB(mobile broadband):移动宽带
HQ(headquarters):总部
CBG(Consumer Business Group):消费者BG,组织与部门
CNBG(Carrier Network BG):运营商BG,当前业务范围。
EBG(Enterprise Business Group):企业业务BG,业务范围例如:数字能源、煤矿、钢铁
DOU(dataflow of usage):平均每月每用户数据流量。
Throughput:吞吐率,网络在不丢包的情况下,被测对象(系统、设备、特定连接、特定服务类等)所能达到的最大传输速度。可以用带宽来度量吞吐量。
SAU
PDP
ROI(return on investment):投资回收率
ARPU(average revenue per user):单一用户之营收贡献度,常用来指网络运营商或服务提供商从每个用户身上得到的平均收入。
2B(to business):面向企业客户
2C(to consumer):面向消费者
ATPC 自动发射功率控制
TCO(Total Cost of Operation):总运营成本
https://zh.wikipedia.org/zh-cn/Apache_Hadoop
https://hadoop.apache.org/
Apache Hadoop 是一个开源软件框架,它使用简单的编程模型提供高度可靠的大型数据集分布式处理。Hadoop 以其可扩展性而闻名,它构建在商用计算机集群上,为存储和处理大量结构化、半结构化和非结构化数据提供了经济高效的解决方案,且没有格式要求。
Apache Hadoop的核心模块分为存储和计算模块。Apache Hadoop框架由以下基本模块构成:
Hadoop Common – 包含了其他 Hadoop 模块所需的库和实用程序;在0.20及以前的版本中,包含HDFS、MapReduce和其他项目公共内容,从0.21开始HDFS和MapReduce被分离为独立的子项目,其余内容为Hadoop Common
Hadoop Distributed File System (HDFS,Hadoop分布式文件系统) – 一种将数据存储在集群中多个节点中的分布式文件系统,能够提供很高的带宽;
Hadoop MapReduce – 用于大规模数据处理的MapReduce计算模型实现;
Hadoop YARN – (于2012年引入) 一个负责管理集群中计算资源,并实现用户程序调度的平台;
Hadoop Ozone – (于2020年引入) Hadoop的对象存储。
Apache Hadoop的MapReduce和HDFS模块的灵感来源于Google的 MapReduce 和 Google File System 论文。
大致工作流程:Hadoop框架先将文件分成数据块并分布式地存储在集群的计算节点中,接着将负责计算任务的代码传送给各节点,让其能够并行地处理数据。这种方法有效利用了数据局部性,令各节点分别处理其能够访问的数据。与传统的超级计算机架构相比,这使得数据集的处理速度更快、效率更高。
https://www.ibm.com/cn-zh/topics/hdfs
[HDFS概述介绍及其优缺点](https://blog.csdn.net/mr123666/article/details/103310926)
HDFS 是一种分布式文件系统,用于处理在商业硬件上运行的大型数据集。 它用于将单个 Apache Hadoop 集群扩展到数百 (甚至数千)个节点。 HDFS 不应与 Apache HBase 混淆或被 Apache HBase 取代,Apache HBase 是一个面向列的非关系数据库管理系统,它位于 HDFS 之上,可以通过其内存处理引擎更好地支持实时数据需求。
https://www.ibm.com/cn-zh/topics/mapreduce
MapReduce 是一种编程范式,它允许在 Hadoop 聚类中的数百或数千台服务器之间进行大规模扩展。 作为处理组件,MapReduce 是 Apache Hadoop 的核心。 术语“MapReduce”指的是 Hadoop 程序执行的两个不同的独立任务。 第一个是映射作业,它接受一组数据,并将其转换为另一组数据,其中各个元素分解为元组(键/值对)。
缩减作业以映射的输出作为输入,并将这些数据元组组合为更小的一组元组。 正如名称 MapReduce 的顺序所暗示的那样,缩减作业总是在映射作业之后执行。
MapReduce 编程提供了一些优势,有助于从您的大数据获得宝贵的洞察:
https://zh.wikipedia.org/zh-cn/Apache_HBase
https://HBase.apache.org/
https://www.ibm.com/cn-zh/topics/HBase
Hadoop database 的简称。是一款基于 Hadoop HDFS 的数据库,是一种NoSQL数据库,主要适用于海量明细数据(十亿、百亿)的随机实时查询,如日志明细、交易清单、轨迹行为等。
HBase 是一个在 HDFS 上运行的列式存储非关系数据库管理系统。 HBase 提供了存储稀疏数据集的容错方式,这类数据集在许多大数据用例中十分常见。 它非常适合实时数据处理或者对大量数据的随机读取/写入访问。
与关系数据库系统不同,HBase 不支持 SQL 一类的结构化查询语言;事实上,HBase 根本不是关系数据存储库。 HBase 应用程序以 Java 编写,更像是一款典型的 Apache MapReduce 应用程序。 HBase 确实支持以 Apache Avro、REST 和 Thrift 编写应用程序。
HBase 系统设计为线性扩展。 它包括一系列由行和列组成的标准表,更像是传统数据库。 每个表必须有一个定义为主键的元素,且所有对 HBase 表的访问尝试都必须使用此主键。
Avro 作为组件,支持一系列丰富的原始数据类型(包括数字、二进制数据和字符串)以及多种复杂类型(包括数组、映射、枚举和记录)。 对于数据,也可以定义排序顺序。
HBase 依赖于 zookeeper 实现高性能协调。 zookeeper 内置到 HBase 中,但如果您正在运行生产集群,那么建议您配备一个与 HBase 集成的专用 ZooKeeper 集群。
HBase 非常适合与 Hive 结合使用,后者是用于大数据批处理的查询引擎,以支持容错性大数据应用程序。
维基百科
HBase是一个开源的<font color="red">非关系型分布式数据库(NoSQL)</font>,它参考了谷歌的BigTable建模,实现的编程语言为 Java。它是Apache软件基金会的Hadoop项目的一部分,运行于HDFS文件系统之上,为 Hadoop 提供类似于BigTable 规模的服务。因此,它可以对稀疏文件提供极高的容错率。 HBase在列上实现了BigTable论文提到的压缩算法、内存操作和布隆过滤器。HBase的表能够作为MapReduce任务的输入和输出,可以通过Java API来访问数据,也可以通过REST、Avro或者Thrift的API来访问。 虽然最近性能有了显著的提升,HBase 还不能直接取代SQL数据库。如今,它已经应用于多个数据驱动型网站,包括 Facebook的消息平台。 在 Eric Brewer的 [CAP理论](https://zh.wikipedia.org/zh-cn/CAP%E5%AE%9A%E7%90%86) 中,HBase属于CP类型的系统。
总结:
https://zh.wikipedia.org/zh-cn/Apache_Hive
https://hive.apache.org/
Hive 是基于Hadoop的一个<font color="red">数据仓库工具</font>,<font color="red">可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,并将SQL语句最终转换为 **MapReduce** 任务进行运行。</font>主要是让开发人员能够通过 SQL 来计算和处理 HDFS 上的结构化数据,**适用于离线的批量数据计算**。
Apache Hive 是一种分布式、容错的数据仓库系统,可实现大规模分析。<font color="red">Hive Metastore (HMS) 提供了一个元数据的中央存储库,</font>可以轻松分析该元数据以做出明智的、数据驱动的决策,因此它是许多数据湖架构的关键组件。Hive 构建在 Apache Hadoop 之上,通过 hdfs 支持 S3、adls、gs 等存储。Hive 允许用户使用 SQL 读取、写入和管理分布式存储中的 PB 级数据。
通过元数据来描述 HDFS 上的结构化文本数据,通俗点来说,就是定义一张表来描述HDFS上的结构化文本,包括各列数据名称,数据类型是什么等,方便我们处理数据,当前很多SQL ON Hadoop的计算引擎均用的是hive的元数据,如Spark SQL、Impala等;
总结:
<font color="blue">**Hive Metastore (HMS)**</font> 是关系数据库中 Hive 表和分区 元数据的中央存储库,并为客户端**(包括 Hive、Impala 和 Spark)**提供使用 Metastore 服务 API 访问此信息的能力。它已成为利用各种开源软件(例如 Apache Spark 和 Presto)的数据湖的构建块。事实上,整个工具生态系统(开源工具和其他工具)都是围绕 Hive Metastore 构建的,此图展示了其中一些工具。
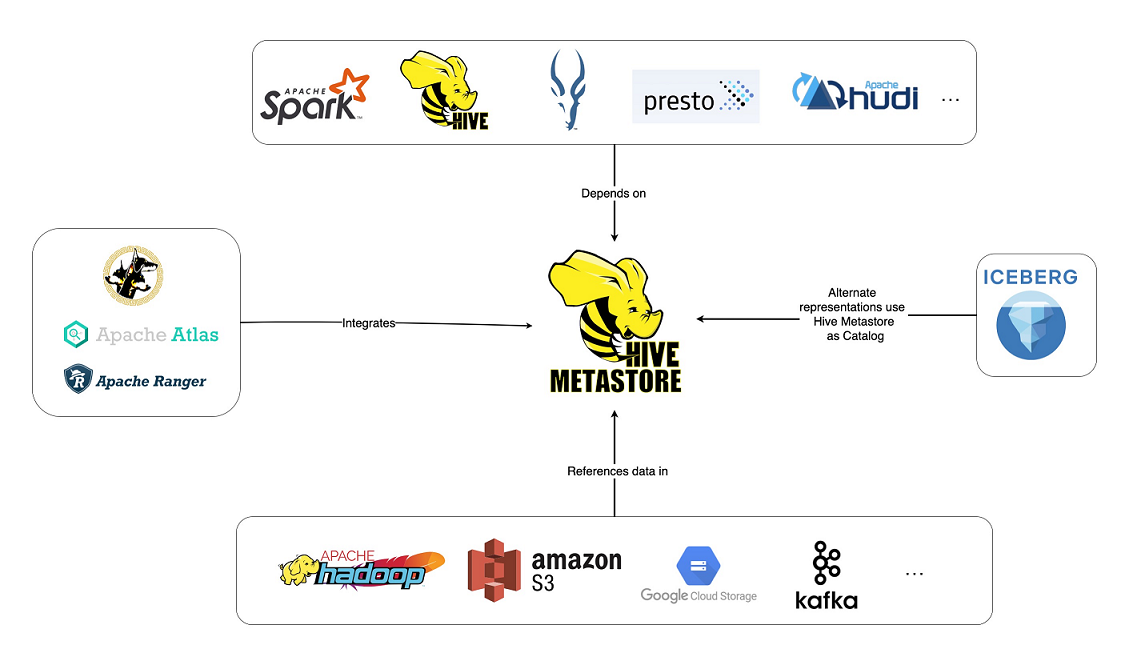
HBase和Hive在大数据架构中处在不同位置,HBase主要解决实时数据查询问题,Hive主要解决数据处理和计算问题,一般是配合使用。
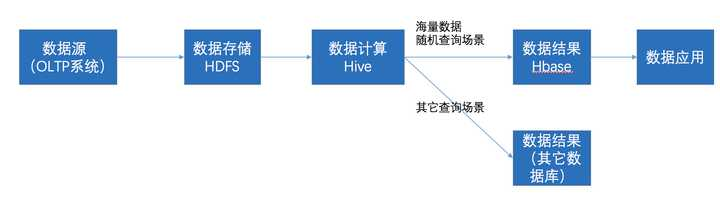
在大数据架构中,Hive和HBase是协作关系,数据流一般如下图:
Impala是用于处理存储在Hadoop集群中的大量数据的MPP(大规模并行处理)SQL查询引擎。 它是一个用C ++和Java编写的开源软件。与其他Hadoop的SQL引擎相比,它提供了高性能和低延迟。
优点
缺点
| Impala | 关系型数据库 |
|---|---|
| Impala使用类似于HiveQL的类似SQL的查询语言 | 关系数据库使用SQL语言 |
| 在Impala中,您无法更新或删除单个记录 | 在关系数据库中,可以更新或删除单个记录 |
| Impala不支持事务 | 关系数据库支持事务 |
| Impala不支持索引 | 关系数据库支持索引 |
| Impala存储和管理大量数据(PB) | 与Impala相比,关系数据库处理的数据量较少(TB) |
相同点
不同点
| HBase | Hive | Impala |
|---|---|---|
| HBase是基于Apache Hadoop的宽列存储数据库。 它使用BigTable的概念。 | Hive是一个数据仓库软件。 使用它,我们可以访问和管理基于Hadoop的大型分布式数据集。 | Impala是一个管理,分析存储在Hadoop上的数据的工具。 |
| HBase的数据模型是宽列存储。 | Hive遵循关系模型。 | Impala遵循关系模型。 |
| HBase是使用Java语言开发的。 | Hive是使用Java语言开发的。 | Impala是使用C ++开发的。 |
| HBase的数据模型是无模式的。 | Hive的数据模型是基于模式的。 | Impala的数据模型是基于模式的。 |
| HBase提供Java,RESTful和Thrift API。 | Hive提供JDBC,ODBC,Thrift API。 | Impala提供JDBC和ODBC API。 |
| 支持C,C#,C ++,Groovy,Java PHP,Python和Scala等编程语言。 | 支持C ++,Java,PHP和Python等编程语言。 | Impala支持所有支持JDBC / ODBC的语言。 |
| HBase提供对触发器的支持。 | Hive不提供任何触发器支持。 | Impala不提供对触发器的任何支持。 |