11Java正则表达式
推荐:
重用正则总结
1 | ([a-zA-Z -]*)([0-9]*) # 利用捕获组匹配,可匹配字符串示例:"abc90"、"90",第一组为字符串(空或abc),第二组为数字(90)。 |
正则表达式
定义
- 正则表达式定义了字符串的模式。
- 正则表达式可以用来搜索、编辑或处理文本。
- 正则表达式并不仅限于某一种语言,但是在每种语言中有细微的差别。
转义
- 在 Java 中,
\\表示:我要插入一个正则表达式的反斜线,所以其后的字符具有特殊意义。 - 在其他语言中(如Perl),一个反斜杠
\就足以具有转义的作用,而在 Java 中则需要有两个反斜杠才能被解析为其他语言中的转义作用。 - Java 的正则表达式中,两个
\\代表其他语言中的一个\,这也就是为什么表示一位数字的正则表达式是\\d,而表示一个普通的反斜杠是\\\\。
常用元字符
^ 、 $ 、 * 、 + 、 ? 、 [a-z] 、 \w 、 \W 、 {n, m}
常见规则
1 | A:字符 |
String类
String 类中有几个可以使用正则的方法,实际都是通过调用 Pattern、Matcher 类实现的
1 | // 判断功能 |
Pattern和Matcher类
Pattern 类:正则表达式的编译表示,没有公共构造方法。
使用方法:正则表达式字符串先被编译为此类的实例,然后用得到的 Pattern 对象创建 Matcher 对象。执行 matcher 方法后的所有匹配都驻留在匹配器 Matcher 中,所以多个匹配器可以共享同一模式。
1 | public static Pattern compile(String regex) // 将给定的正则表达式编译成一个模式。 |
Matcher 类:没有公共构造方法。
通过解释 Pattern 对字符序列执行匹配操作的引擎。
匹配器通过调用 Pattern 的 matcher 方法创建一个 Matcher 对象。创建后,Matcher 可用于执行三种不同类型的匹配操作:
- matches 方法尝试将整个输入序列与模式匹配。
- lookingAt 方法尝试将输入序列与模式匹配,从头开始。
- find 方法扫描输入序列以查找与模式匹配的下一个子序列。
每个方法都返回一个表示成功或失败的布尔值。通过查询匹配器的状态可以获取关于成功匹配的更多信息。
如果匹配成功,则可以通过 start、end 和 group 方法获取更多信息。
1 | public boolean matches():尝试将整个区域与模式匹配。 |
PatternSyntaxException 类:一个非强制异常类,它表示一个正则表达式模式中的语法错误。
具体使用说明及更多方法见 API。
典型调用顺序
1 | Pattern p = Pattern.compile("a*b"); // 正则表达式字符串先被编译为Pattern实例。 |
练习
1 | /* |
捕获组
- 捕获组是把多个字符当一个单独单元进行处理的方法,它通过对括号内的字符分组来创建。
- 捕获组是通过从左至右计算其开括号来编号。例如,在表达式
((A)(B(C))),有四个这样的组:((A)(B(C)))、(A)、(B(C))、(C)。 - Matcher 类的 groupCount 方法返回一个 int 值,表示 Matcher 对象有多个捕获组。
- group(0) 是一个特殊的组,代表整个表达式。该组不包括在 groupCount 的返回值中。
用法:
1 | public class RegexDemo { |
输出:
1 | Found value: This order was placed for QT3000! OK? |
正则注入(regex injection)
定义
攻击者可能会通过恶意构造的输入对初始化的正则表达式进行修改,比如导致正则表达式不符合程序规定要求;可能会影响控制流,导致信息泄露,或导致ReDos攻击。
避免使用不可信数据构造正则表达式。
利用方式
- 匹配标志:不可信的输入可能覆盖匹配选项,然后有可能会被传给
Pattern.compile()方法。 - 贪赞:一个非受信的输入可能试图注入一个正则表达式,通过它来改变初始的那个正则表达式,从而匹配尽可能多的字符串,从而暴露敏感信息。
- 分组:程序员会用括号包括一部分的正则表达式以完成一组动作中某些共同的部分。攻击者可能通过提供非受信的输入来改变这种分组。
输入校验
- 非受信的输入应该在使用前净化,从而防止发生正则表达式注入。
- 当用户必须指定正则表达式作为输入时,必须注意需要保证初始的正则表达式没有被无限制修改。
- 在用户输入字符串提交给正则解析之前,进行白名单字符处理 (比如字母和数字)。
- 开发人员必须仅仅提供有限的正则表达式功能给用户,从而减少被误用的可能。
ReDos攻击
正则表达式拒绝服务( ReDoS ) 是一种算法复杂性攻击,它通过提供 正则表达式 或 需要很长时间评估的输入 来产生拒绝服务(即:通过提供特制的正则表达式或输入来使程序花费大量时间,消耗系统资源,然后程序将变慢或变得无响应)。
ReDos攻击概述
- JDK 中提供的正则匹配使用的是 NFA 引擎。
- NFA 引擎具有回溯机制(一个字符可能尝试多次匹配),匹配失败时花费时间很大。 正则表达式回溯法原理
- 当使用简单的非分组正则表达式时,是不会导致ReDos攻击的。
潜在危险
- 包含具有自我重复的重复性分组的正则
举例:^(\d+)+$、^(\d*)*$、^(\d+)*$、^(\d+|\s+)*$ - 包含替换的重复性分组
举例:^(\d|\d|\d)+$、^(\d|\d?)+$
当输入字符串为
1111111111111111111111x1时,正则表达式^(\d+)+$就会不断进行失败重试,从而耗死CPU计算。解析:
\d+表示匹配一个或多个数字;()+表示分组本身也匹配一个或多个;那么匹配字符串1111111111111111111111x1就会进行非常多的尝试,从而导致CPU资源枯竭。
规避猎施
- 进行正则匹配前,先对匹配的文本的长度进行校验。
- 在编写正则时,尽量不要使用过于复杂的正则,越复杂越容易有缺陷。
- 在编写正则时,尽量减少分组的使用。
- 避免动态构建正则(因为难以判断是否有性能问题),当使用不可信数据构造正则时,要使用白名单进行严格校验。
案例
校验qq号码
1 | /* |
用正则表达式改进:
1 | public class RegexDemo { |
校验电话号码和邮箱

按照不同的规则分割数据
一:
1 | /* |
二:
1 | /* |
三:
1 | /* |
把论坛中的数字替换为*
1 | /* |
获取字符串中由3个字符组成的单词
1 | /* |
09Java常用类4之集合
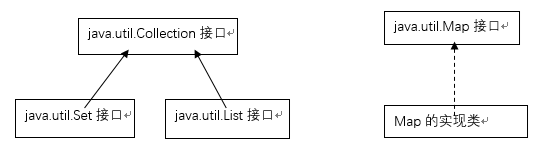
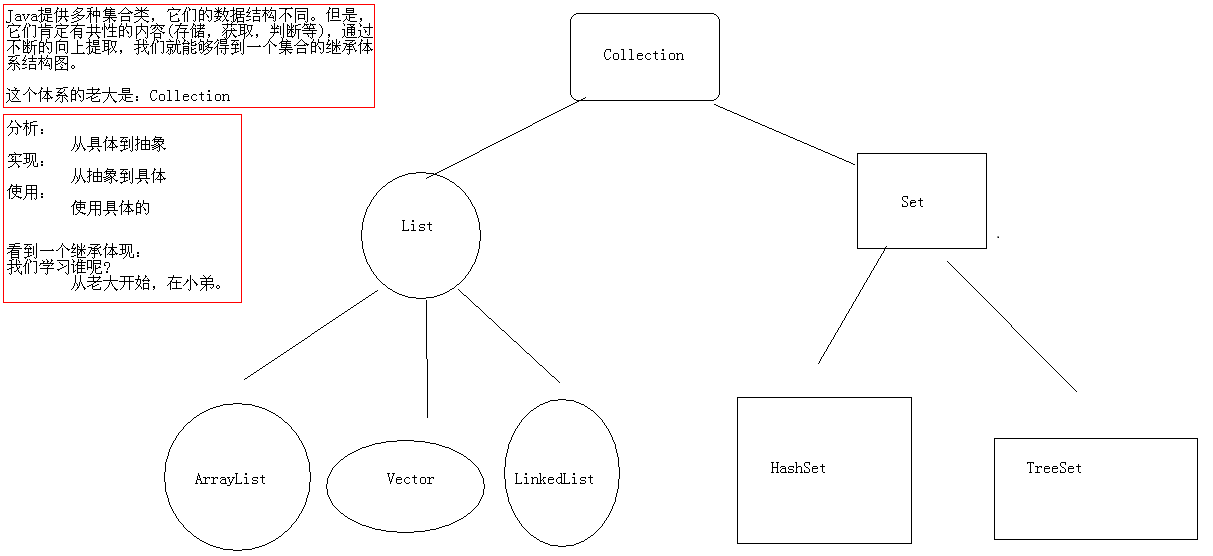
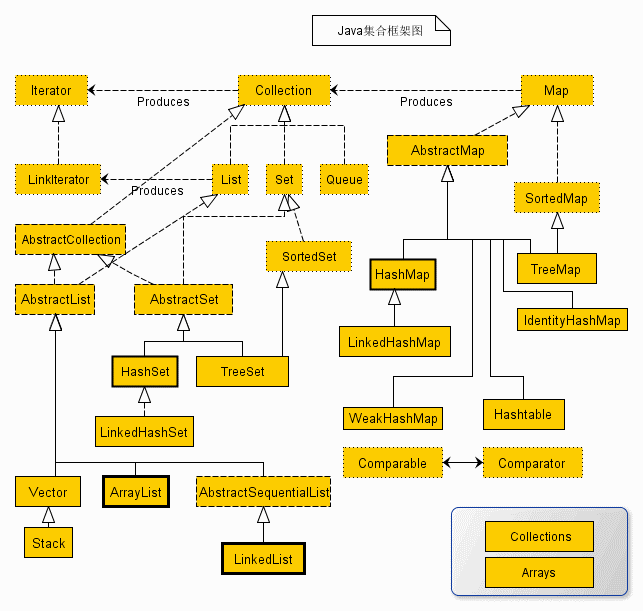
常用集合结构
线性结构
- List:ArrayList、CopyOnWriteArrayList、Vector
- Queue: LinkedList、PriorityQueue、BlockingQueue、ConcurrentLinkedQueue
- Stack:extends from Vector
非线性结构
- Set:HashSet、LinkedHashSet、TreeSet、CopyOnWriteArraySet、ConcurrentSkipListSet
- Map:HashMap、TreeMap、WeakHashMap、IdentityHashMap、 LinkedHashMap 、 HashTable、ConcurrentHashMap、 ConcurrentSkipListMap
集合包装类
集合包装类可以对上述的几种结构进行包装,而它在其中的返回会加入它的语义理解
- 不可变更集合类:Collections.unmodifiableCollection,对上述结构的限定,返回不可修改的集合
- 同步集合类:Collections.synchronizedCollection,可以将任意List转换成线程安全的List
- 可检查集合类:Collections.checkedCollection
注:其中 斜体 标注的类为线程安全类。
线性存储结构
重点选讲以 List 展开的类
ArrayList
- 可设置初始的空间大小,在底层数组不够用时在原来的基础上扩容1.5倍
Vector
- 可设置初始的空间大小,在底层数组不够用时在原来的基础上默认扩容2倍 (亦可设置增长的空间大小)
- 读写方法都加了synchronized关键字,是线程安全的
CopyOnWriteArrayList
- 利用写时复制的思想,一旦碰到写操作都会对所有元素进行复制
- 在新的数组上修改后,重新对数组赋值引用,保证线程安全
- 适合读多写少的应用场景
ConcurrentLinkedQueue
- 非阻塞式队列,利用CAS算法保证入队出队线程安全
- 进行元素遍历时是线程不安全
- 不允许添加null元素
映射关系
WeakHashMap
- 适用于需要缓存的场景,对entry进行弱引用管理
- GC时会自动释放弱引用的entry项
- 相对HashMap只增加弱引用管理,并不保证线程安全
HashTable
- 读写方法都加了synchronized关键字
- key和value都不允许出现null值
- 与HashMap不同的是HashTable直接使用对象的hashCode,不会重新计算hash值
ConcurrentHashMap
- 利用CAS+ Synchronized来确保线程安全
- 底层数据结构依然是数组+链表+红黑树
- 对哈希项进行分段上锁,效率上较之HashTable要高
- key和value都不允许出现null值
问题:
为什么ConcurrentHashMap不允许插入Null值?
小测
ArrayList list = new ArrayList(20); 中的 List 扩充了几次?
初始化时直接分配大小,不存在扩充情况,所以是0次;add等操作时才可能会发生扩充。
08Java常用类3
Math类
包含用于执行基本数学运算的方法,如初等指数、对数、平方根和三角函数。
1、针对数学运算进行操作的类
2、常见方法(更多方法见API)
1 | 成员变量: |
案例:
A:猜数字小游戏
B:获取任意范围的随机数
1 | /* |
Random类
1.用于产生随机数的类
如果用相同的种子创建两个 Random 实例,则对每个实例进行相同的方法调用序列,它们将生成并返回相同的数字序列。
2.构造方法:
A:Random():创建一个新的随机数生成器。此构造方法将随机数生成器的种子设置为某个值,该值与此构造方法的所有其他调用所用的值完全不同。
没有给种子,用的是默认种子,是当前时间的毫秒值,每次产生的随机数不同
B:Random(long seed): 使用单个 long 种子创建一个新的随机数生成器。该种子是伪随机数生成器的内部状态的初始值,该生成器可通过方法 protected int next(int bits) 维护。
指定种子,每次种子相同,随机数就相同
3.成员方法:
A:int nextInt() 返回int范围内的随机数
1 | // nextInt方法源码 |
B:int nextInt(int n) 返回[0,n)范围内的随机数
1 | public class RandomDemo { |
System类
1.System 类包含一些有用的 类 字段和方法。System 类不能被实例化。
在 System 类提供的设施中,有标准输入、标准输出和错误输出流;对外部定义的属性和环境变量的访问;加载文件和库的方法;还有快速复制数组的一部分的实用方法。
解析:说明字段和方法都是跟类相关的,跟类相关不就是静态的么,说明没有构造方法。
2.成员方法(更多方法见API)
1 | A: public static void gc():运行垃圾回收器 |
案例:
A. 运行垃圾回收器
System.gc()可用于垃圾回收。当使用System.gc()回收某个对象所占用的内存之前,通过要求程序调用适当的方法来清理资源。在没有明确指定资源清理的情况下,Java提高了默认机制来清理该对象的资源,也就是调用Object类的finalize()方法。finalize()方法的作用是释放一个对象占用的内存空间时,会被JVM调用。而子类重写该方法,就可以清理对象占用的资源,该方法没有链式调用,所以必须手动实现。
从程序的运行结果可以发现,执行System.gc()前,系统会自动调用finalize()方法清除对象占有的资源,通过super.finalize()方式可以实现从下到上的finalize()方法的调用,即先释放自己的资源,再去释放父类的资源。
但是,不要在程序中频繁的调用垃圾回收,因为每一次执行垃圾回收,jvm都会强制启动垃圾回收器运行,这会耗费更多的系统资源,会与正常的Java程序运行争抢资源,只有在执行大量的对象的释放,才调用垃圾回收最好
1 | public class RandomDemo { |
B. 退出jvm
public static void exit(int status)
终止当前正在运行的 Java 虚拟机。参数用作状态码;根据惯例,非 0 的状态码表示异常终止。
该方法调用 Runtime 类中的 exit 方法。该方法永远不会正常返回。
调用 System.exit(n) 实际上等效于调用:
Runtime.getRuntime().exit(n)
C. 获取当前时间的毫秒值
1 | public class SystemDemo { |
D. 数组复制
1 | public class SystemDemo { |
BigInteger类
大数字
a. java.math.BigInteger:整数
b. java.math.BigDecimal:浮点数
1、针对大整数的运算(BigInteger:可以让超过Integer范围内的数据进行运算)
2、构造方法
A:BigInteger(String s)
1 | public class BigIntegerDemo { |
3、成员方法(更多方法见API)
A: public BigInteger add(BigInteger val):加
B: public BigInteger subtract(BigInteger val):减
C: public BigInteger multiply(BigInteger val):乘
D: public BigInteger divide(BigInteger val):除
E: public BigInteger[] divideAndRemainder(BigInteger val):返回商和余数的数组
1 | public class BigIntegerDemo { |
BigDecimal类
1 | /* |
1、浮点数据做运算,会丢失精度。所以,针对浮点数据的操作建议采用BigDecimal。(金融相关的项目)
2、构造方法
A:BigDecimal(String s)
3、成员方法:
A: public BigDecimal add(BigDecimal augend):加
B: public BigDecimal subtract(BigDecimal subtrahend):减
C: public BigDecimal multiply(BigDecimal multiplicand):乘
D: public BigDecimal divide(BigDecimal divisor):除
E: public BigDecimal divide(BigDecimal divisor,int scale,int roundingMode):商,几位小数,如何舍取
divisor - 此 BigDecimal 要除以的值。
scale - 要返回的 BigDecimal 商的标度。
roundingMode - 要应用的舍入模式。
F: public BigDecimal divide(BigDecimal divisor, int scale, RoundingMode roundingMode):商,几位小数,如何舍取
1 | public class BigDecimalDemo { |
日期相关类
A. java.util.Date类:最常用的功能为获得系统的当前时间。
B. java.util.Calendar类:与日历相关的类。可以获得日期相关的信息,还可以进行日期的计算。
C. java.text.DateFormat及其子类:可以对String与Date进行相互的转换。
1 | /*********************************************************************/ |
Date
类 Date 表示特定的瞬间,精确到毫秒。
A:构造方法
public Date():创建自 1970 年 1 月 1 日 00:00:00 GMT 到当前的默认毫秒值的日期对象
public Date(long time):创建自 1970 年 1 月 1 日 00:00:00 GMT 到给定的毫秒值的日期对象
1 | public class DateDemo { |
B:成员方法
public long getTime():返回自 1970 年 1 月 1 日 00:00:00 GMT 以来此 Date 对象表示的毫秒数。
public void setTime(long time):设置此 Date 对象,以表示 1970 年 1 月 1 日 00:00:00 GMT 以后 time 毫秒的时间点。
1 | public class DateDemo { |
C:日期和毫秒值的相互转换
案例:你来到这个世界多少天了?
1 | /* |
DateFormat
针对日期进行格式化和针对字符串进行解析的类,但是是抽象类,所以使用其子类SimpleDateFormat
A: SimpleDateFormat的构造方法:
public SimpleDateFormat():用默认的模式和默认语言环境的日期格式符号构造 SimpleDateFormat。
public SimpleDateFormat(String pattern): 用给定的模式和默认语言环境的日期格式符号构造 SimpleDateFormat。
这个模式字符串该如何写呢? 通过查看API,我们就找到了对应的模式
y 年
M 年中的月份
d 月份中的天数
H 一天中的小时数(0-23)
m 小时中的分钟数
s 分钟中的秒数
yyyy-MM-dd HH:mm:ss 2017-05-01 12:12:12
yyyy年MM月dd日 HH:mm:ss 2017年05月01日 12:12:12
B:日期和字符串的转换
a:Date – String(格式化)
public final String format(Date date)
b:String – Date(解析)
public Date parse(String source)
1 | public class DateFormatDemo { |
C:制作了一个针对日期操作的工具类。

日期类的时间从为什么是从1970年1月1日
I suspect that Java was born and raised on a UNIX system.
UNIX considers the epoch (when did time begin) to be midnight, January 1, 1970.
是说java起源于UNIX系统,而UNIX认为1970年1月1日0点是时间纪元.
但这依然没很好的解释”为什么”,出于好奇,继续Google,总算找到了答案:
http://en.wikipedia.org/wiki/Unix_time
这里的解释是:
最初计算机操作系统是32位,而时间也是用32位表示。
System.out.println(Integer.MAX_VALUE);
2147483647
Integer在JAVA内用32位表 示,因此32位能表示的最大值是2147483647。
另外1年365天的总秒数是31536000,
2147483647/31536000 = 68.1
也就是说32位能表示的最长时间是68年,而实际上到2038年01月19日03时14分07
秒,便会到达最大时间,过了这个时间点,所有32位操作系统时间便会变为
10000000 00000000 00000000 00000000
也就是1901年12月13日20时45分52秒,这样便会出现时间回归的现象,很多软件便会运行异常了。
到这里,我想问题的答案已经出来了:
因为用32位来表示时间的最大间隔是68年,而最早出现的UNIX操作系统考虑到计算
机产生的年代和应用的时限综合取了1970年1月1日作为UNIX TIME的纪元时间(开始
时间),而java自然也遵循了这一约束。
至于时间回归的现象相信随着64为操作系统的产生逐渐得到解决,因为用64位操作
系统可以表示到292,277,026,596年12月4日15时30分08秒,相信我们的N代子孙,哪
怕地球毁灭那天都不用愁不够用了,因为这个时间已经是千亿年以后了。
最后一个问题:上面System.out.println(new Date(0)),打印出来的时间是8点而非0点,
原因是存在系统时间和本地时间的问题,其实系统时间依然是0点,只不过我的电脑时区
设置为东8区,故打印的结果是8点。
Calendar类
它为特定瞬间与一组诸如 YEAR、MONTH、DAY_OF_MONTH、HOUR 等 日历字段 之间的转换提供了一些方法,并为操作日历字段(例如获得下星期的日期)提供了一些方法。
1、日历类,封装了所有的日历字段值,通过统一的方法根据传入不同的日历字段可以获取值。
2、如何得到一个日历对象呢?
Calendar rightNow = Calendar.getInstance();// 使用默认时区和语言环境获得一个日历。返回的 Calendar 基于当前时间,使用了默认时区和默认语言环境。
本质返回的是子类对象
3、成员方法
A: public int get(int field):返回给定日历字段的值。日历类中的每个日历字段都是静态的成员变量,并且是int类型
B: public void add(int field,int amount): 根据日历的规则,为给定的日历字段添加或减去指定的时间量。
C: public final void set(int year,int month,int date): 设置日历字段 YEAR、MONTH 和 DAY_OF_MONTH 的值。
1 | public class CalendarDemo { |
- 案例:
1 | /* |
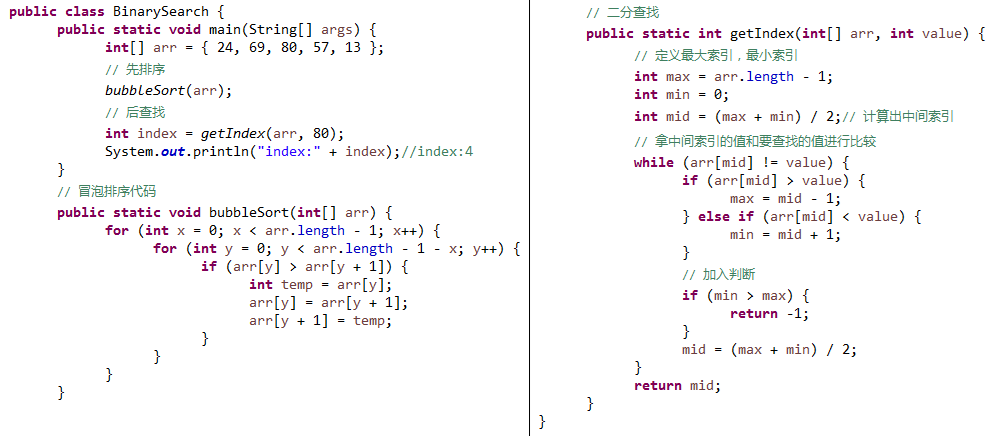
二分查找(二分法)
查找:
基本查找:数组元素无序(从头找到尾)
二分查找(折半查找):数组元素有序
数组高级二分查找原理图解:
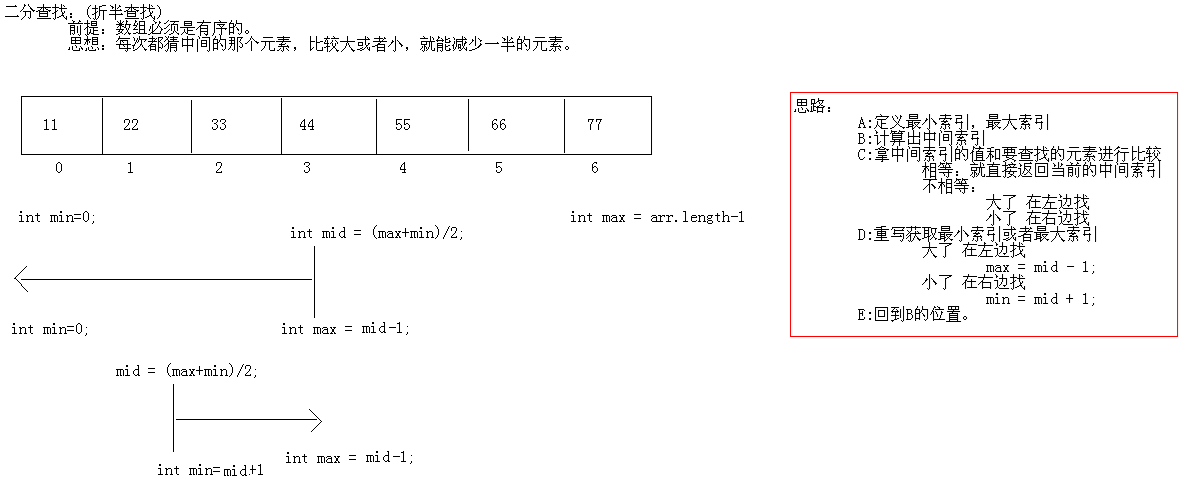
代码:

注意:下面这种做法是有问题的。
因为数组本身是无序的,所以这种情况下的查找不能使用二分查找。
所以你先排序了,但是你排序的时候已经改变了我最原始的元素索引。
必须使用基本查找,除非需求不在意。
十大排序算法
07Java常用类2之包装类
包装类
定义
包装类的作用:基本类型不是类,所以无法获得类的基本特性,无法参与转型、泛型、集合、反射等过程,包装类的出现就是为了弥补这个缺陷。
为了对基本类型的数据进行更多的操作,将 基本数据类型 封装成类,并在类中定义一些功能,这个类就是 包装类(8个)。
byte Byte
short Short
int Integer
long Long
float Float
double Double
char Character
boolean Boolean
常见的操作之一:用于基本数据类型与字符串之间的转换。
装箱与拆箱
装箱
将 基本数据类型 转换为 包装类类型。
自动装箱 基本类型 – 包装类类型(引用类型)
拆箱
将 包装类类型 转换为 基本数据类型。
自动拆箱 包装类类型(引用类型)– 基本类型
自动装箱与拆箱
从JDK1.5开始可以自动装箱与拆箱。所以下面是正确的:
1 | Integer num1 = 100; |
Integer
Integer 类在对象中包装了一个基本类型 int 的值。Integer 类型的对象包含一个 int 类型的字段。
此外,该类提供了多个方法,能在 int 类型和 String 类型之间互相转换,还提供了处理 int 类型时非常有用的其他一些常量和方法。
构造方法
1 | public Integer(int value) |
成员方法
1 | public static final int MAX_VALUE |
A. String、包装类、基本数据类型 的相互转换
1 | public int intValue() |
B. 进制转换(了解)
1 | public static String toBinaryString(int i) |
案例
-128到127之间的数据缓冲池问题
注意:Integer的数据直接赋值,如果在-128到127之间,会直接从缓冲池里获取数据
1 | public class IntegerDemo { |
Character(了解)
Character 类在对象中包装一个基本类型 char 的值。Character 类型的对象包含类型为 char 的单个字段。
此外,该类提供了几种方法,以确定字符的类别(小写字母,数字,等等),并将字符从大写转换成小写,反之亦然。
字符信息基于 Unicode 标准,版本 4.0。
构造方法
1 | public Character(char value) |
成员方法
1 | A. public static boolean isUpperCase(char ch): 判断给定的字符是否是大写 |
案例
统计字符串中大写,小写及数字字符出现的次数
1 | public class IntegerDemo { |
弊端
包装类的弊端,不断地拆装箱会引发性能问题:
1 | public class Test { |
重载和自动拆装箱
有更匹配的重载方法时,不自动拆装箱
1 | public class Test { |
常量池
注意:包装类的比较必须使用equals(), ‘==’ 比较的是两个引用是否指向一个对象。
包装类的创建很浪费性能,因此Java对简单的数字(-128~127)对应的包装类进行了缓存,称为常量池。通过直接量赋值的包装类如果在此范围内,会直接使用常量池中的引用。
1 | public class Test { |